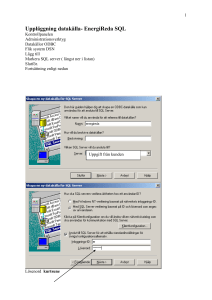
ETL-verktyg för datavaruhus
advertisement

ETL-verktyg för datavaruhus Examensarbete vid institutionen för datavetenskap Umeå Universitet Författare: Johan Unger <[email protected]> Handledare: Tommy Jakobsen (ABB Power Technology Products AB) Johan Karlsson (Umeå Universitet) Datum måndag den 21 januari 2002 Sammanfattning Detta examensarbete har huvudsakligen bestått av tre delar: 1. Studie av datavaruhus med fokusering på ETL (Extraction, Transformation & Loading). 2. Teoretisk jämförelse, analys och val av ETL-verktyg (PowerMart eller DTS). 3. Design och implementation av datavaruhus och ETL-processer, samt framtagande av gränssnitt för rapporter och analyser. Arbetet inleddes med en teoretisk studie av datavaruhus och ETL. Från de kunskaper som inhämtades under denna studie och de direkta behov som identifierades på ABB, utvecklades en metod för analysera ETL-verktyg. Metoden bestod av ett antal mätparametrar, som beskrev behoven för laddningen av datavaruhuset, vilka möjliggjorde en analys av verktygen. Valet av ETL-verktyg stod mellan Informatica PowerMart och Microsoft DTS och efter jämförelsen valdes DTS. Efter detta val satte utvecklingen av datavaruhus och ETL igång. Datavaruhuset utvecklades i Microsoft SQL Server 2000 och när datavaruhuset stod färdigt användes Crytsal Report för rapportgenering och Excel 2000 som analysverktyg mot datavaruhuset. Idag finns en testmiljö för datavaruhuset uppe på ABB. Användare kan via ABBs intranät erhålla rapporter och med hjälp av Excel 2000 utföra analyser på data från datavaruhuset. Abstract This master thesis consists of three major parts. 1. Study of data warehouse and ETL (Extraction, Transformation and Loading) 2. Theoretical comparison, analysis and selection of one ETL-tool (PowerMart or DTS). 3. Design and implementation of a data warehouse and ETL-processes, with development of interfaces for reports and analysis. The work started with a theoretical study of data warehouses and ETL. From the knowledge acquired from the study and the direct requirements identified on ABB, a method to analyse ETL-tools was developed. The method contained a number of parameters that described the requirements for the loading of the data warehouse, which made it possible to examine the tools. The choice of ETL-tool stood between Informatica PowerMart and Microsoft DTS and when the analysis was finished the choice fell on DTS. When the choice was made the development of the data warehouse and ETL started. The data warehouse was implemented with Microsoft SQL Server 2000 and when the data warehouse was up, Crystal Report was used to make reports out of the data and Microsoft Excel 2000 was used to analyse the data in the data warehouse. Today there’s a working test environment on ABB. Users can through ABB’s Intranet obtain reports and with Excel 2000 analyse data from the data warehouse. 1 INLEDNING 3 1.1 1.2 1.3 1.4 3 3 4 4 BAKGRUND PROBLEMBESKRIVNING SYFTE OCH MÅL AVGRÄNSNINGAR 2 METOD 2.1 2.2 2.2.1 2.2.2 2.2.3 2.2.4 2.3 2.3.1 2.3.2 2.3.3 2.4 2.4.1 2.4.2 2.4.3 2.4.4 2.4.5 2.4.6 2.4.7 INLEDNING DATAVARUHUS VARFÖR BEHÖVS DATAVARUHUS? DIMENSIONELLA DATABASER STJÄRNMODELLEN DATAFLÖDET ETL ETLS UPPGIFTER FAKTORER SOM PÅVERKAR ETL ANGREPPSSÄTT FÖR ETL JÄMFÖRELSEMETOD IDENTIFIERA BEHOV DEFINIERA OCH VIKTA PARAMETRAR GRUPPERING AV PARAMETER BETYGSSYSTEM BERÄKNING AV PARAMETERGRUPPS BETYG ANALYS AV JÄMFÖRELSEMETODEN RISKER MED JÄMFÖRELSEMETODEN 5 5 5 5 7 9 11 12 12 13 15 16 17 17 18 18 19 19 21 3 ANALYS AV ETL-VERKTYG 22 3.1 3.2 3.2.1 3.2.2 3.2.3 3.2.4 3.2.5 3.3 3.3.1 3.3.2 3.4 3.4.1 3.4.2 3.5 3.6 22 22 23 24 26 27 28 29 29 30 36 36 36 43 44 NULÄGESANALYS FÖR ABB VAL AV PARAMETRAR ANSLUTNINGSMÖJLIGHETER (GRUPP 1) LADDNINGSFUNKTIONALITET (GRUPP 2) ANVÄNDARVÄNLIGHET (GRUPP 3) ADMINISTRATION OCH DRIFT (GRUPP 4) KOSTNADER (GRUPP 5) POWERMART ÖVERBLICK PARAMETRAR DTS ÖVERBLICK PARAMETRAR SAMMANFATTNING AV JÄMFÖRELSEN SLUTSATS ETL-verktyg för datavaruhus 4 GENOMFÖRANDE 45 4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.8 46 46 48 49 52 53 54 54 BASLAGRET LADDNING AV BASLAGER ANALYSLAGRET LADDNING AV ANALYSLAGRET KONFIGURATION AV DTS OLAP-KUBER ANVÄNDARGRÄNSSNITT FÖR OLAP-KUBER ANVÄNDARGRÄNSSNITT FÖR RAPPORTER 5 RESULTAT OCH FRAMTID 55 6 TACK 56 7 ORDLISTA 57 8 KÄLLFÖRTECKNING 58 2 ETL-verktyg för datavaruhus 1 Inledning 1.1 Bakgrund Det här examensarbetet utförs på ABB Power Technology Products AB under Business Area Unit (BAU) Transformers i Ludvika. ABB PTP tillverkar högspänningsprodukter och ingår i den globala teknikkoncernen ABB. Huvudkontoret för ABB ligger i Zürich, Schweiz och antal anställda är ca 165 000 personer i över 100 länder. Antal anställda i Sverige är strax under 20 000 och på BAU-enheten Transformers arbetar ca 500 personer. Transformers ansvarar för försäljning och tillverkning av krafttransformatorer och shuntreaktorer. Vi lever idag i ett informationssamhälle där information samlas och distribueras i snabb takt. Företag är i ständigt behov av analyser och rapporter som bygger på data och information som företaget på olika sätt har tillgång till. Informationen ligger ofta i företagets affärssystem och kan ibland vara spridd över flera heterogena system. Ett behov finns alltså att sammanföra informationen i företaget och strukturera den, för att senare kunna utföra analyser på det insamlade materialet. Det är detta behov som har skapat begreppet Data Warehousing. Ett datavaruhus (Data Warehouse) är ett system som kan hämta data från olika källor, sammanföra det på ett strukturerat sätt som möjliggör att analyser av den insamlade information kan utföras med enkelhet. För att ladda ett datavaruhus behövs ett verktyg som samlar in, bearbetar och slutligen laddar datan till datavaruhuset. ETL-verktyg (Extraction, Transformation, Loading) är ett samlingsbegrepp för dessa verktyg. 1.2 Problembeskrivning ABB PTP Transformer (PTTFO) lagrar idag det mesta av sin information i affärssystemet BaaN. BaaN är ett ERP-system (Enterprise Resource Planning) som används genom hela produktionen, från beställning av råvaror till försäljning till kund. En sak som kännetecknar ett ERP-system är att det är avsett för att lagra information, det är inte direkt anpassat för att visa och analysera sitt data. Det är pga denna begränsning som behovet av ett nytt system föddes, ett system från vilket man kan producera rapporter och genomföra analyser. Det man eftersöker är alltså ett datavaruhus. 1999 inleddes ett datavaruhusprojekt kallat Business Intelligence System (BIS) – Data Warehouse på ABB. Man beslutade sig för att använda Microsoft SQL Server 7.0 (MS SQL 7.0) för själva datavaruhuset och en produkt av BaaN som heter Broadbase som ETL-verktyg. På grund av omprioriteringar och att kompetensen på Broadbase försvann från ABB lades projektet på is hösten 2000. Under sommaren 2001 fick projektet ny vind i seglen, men nu visste man inte vilket ETL-verktyg som skulle användas. Två kandidater kom upp, Microsofts Data Transformation Service (DTS) och Informaticas PowerMart. 3 ETL-verktyg för datavaruhus 1.3 Syfte och mål Syftet med detta examensarbete är att få klarhet i vilket av ETL-verktygen Microsoft DTS och Informatica PowerMart som är lämpligast att använda i ABBs datavaruhuslösning. När ett val av verktygen kan göras ska datavaruhuset designas och implementeras i Microsoft SQL Server 2000. Även prototyper av användargränssnitt för rapporter och analyser ska tas fram. Det som skall uppnås med detta examensarbete är alltså följande: • • • Ett val av ETL-verktygen DTS och PowerMart skall göras efter en jämförelse av hur de lämpar sig för ABBs situation. Datavaruhuset med tillhörande laddningsrutiner skall designas och utvecklas så att det passar för rapportering och analysering av data. Ett förslag på användargränssnitt skall tas fram, där användare från sin arbetsstation kan ta fram rapporter och analysera datan. 1.4 Avgränsningar Även fast detta datavaruhus ska kunna hantera data från flera olika avdelningar kommer endast inköpsdata att tas med i detta projekt. Denna avgränsning görs för att datamängden inte ska bli för stor och för att se att lösningen håller hela vägen, från BaaN till slutanvändare. Dock måste hänsyn tas till att data från andra avdelningar ska kunna tillföras senare. 4 ETL-verktyg för datavaruhus 2 Metod 2.1 Inledning Eftersom detta examensarbete inleddes med en teoretisk jämförelse började jag med att söka litteratur som behandlar datavaruhus och ETL-verktyg. Jag bestämde mig för några böcker som jag tyckte gav ett seriöst intryck och där författaren har god erfarenhet av datavaruhus. För övrigt har Internet varit den stora källan för information och jag har försökt hålla mig till sidor som jag bedömt som trovärdiga. Förutom dessa två källor har jag dessutom haft tillgång till muntliga källor på ABB och produktdokumentation om ETL-verktygen från tillverkarna. För att genomföra en jämförelse av två ETL-verktyg måste man först förstå den miljö där de arbetar. Därför börjar jag i detta kapitel med att beskriva datavaruhus och du som läsare får lära dig vad de används till och de begrepp som används inom detta område. Efter det beskriver jag laddningen av datavaruhus och krav som av olika anledningar ställs på den. Kapitlet avslutas med en beskrivning av den jämförelsemetod jag utvecklat och använt för att jämföra de båda verktygen. 2.2 Datavaruhus 2.2.1 Varför behövs datavaruhus? Företag är i ständigt behov av olika rapporter, sammanställningar och analyser. Det kan handla om lönsamhetsrapporter, sammanställningar av resultat och analyser av kundbeteende. Som tidigare nämnts så är ett datavaruhus en slags samlingsplats för företagsdata, från vilken analyser av datan kan göras på ett enkelt sätt. När datavaruhusen började dyka upp i början av 1990-talet menade man att ett datavaruhus skulle innehålla statisk historisk data samlad under en lång. Gupta [Gupta 1997] ger följande långa definition, fritt översatt: ”ett datavaruhus är en strukturerad utbyggbar miljö avsedd för analyser av ickeföränderlig data, logiskt och fysiskt transformerad från flera källor för att passa företagsstrukturen, uppdaterad och underhållen under en lång tid, uttryckt i enkla företagstermer och summerad för analyser”. Varför behövs nu ett datavaruhus för att analysera data? Datan finns ju redan i företagets olika system, går den inte att analyser därifrån direkt? För att svara på den frågan varför datavaruhus behövs så måste vi titta lite närmare på de system där data ofta ligger lagrat, sk affärssystem. Typiskt för affärssystem är att de är designade för registrering av data med bra stöd för transaktioner, såsom orderbehandling, inventarieföränderingar, och inmatning av data om personal. Flera transaktioner kan utföras samtidigt då dessa system ofta används av flera användare samtidigt. Vanligt är också att data i dessa system ligger lagrat i någon relationsdatabas som är normaliserad till någon nivå. Det som görs med en databas som normaliseras är i grova drag att data delas upp i flera tabeller i stället för att all data ligger i en och samma tabell. Mellan tabellerna finns referenser som gör det möjligt att slå samman tabellerna för att 5 ETL-verktyg för datavaruhus utläsa data. Normalisering av databaser görs för att minska utrymmet för att lagra data och få konsistens i systemet [Elmasri 2000]. Affärssystemen rensas regelbundet på data när transaktioner inte längre är aktuella, för att hålla datavolymerna nere vilket i sin tur höjer prestanda. Vi kan sammanfatta de karaktäristiska dragen för ett affärssystem med följande punkter: • • • • • • Data är ofta lagrat i en relationsdatabas. Normalisering utnyttjas i någon grad för utrymmesbesparing och konsistens. Transaktioner utförs snabbt och över en liten datamängd. Flera transaktioner utförs samtidigt från olika terminaler. Lagrar dynamisk data som uppdateras dagligen. Gammal data töms regelbundet. Kort sagt kan man säga att affärssystem är avsedda för inmatning av data rörande företagets produktion på en detaljerad nivå, men för analyser ska vi nu se att det behövs ett annat system. Ett företag har sällan all sin data lagrad i ett enda system, utan ofta används flera olika system för olika uppgifter. Det kan handla om allt från stora affärssystem till mindre specifika databaser för lokala lösningar. För att utföra analyser av data från flera heterogena system måste datan sammanföras till en homogen plats. Om man dessutom vill analysera trender över flera år så måste data finnas lagrad för flera år, vilket det vanligtvis inte finns i affärssystem. Detta medför att stora datamängder måste lagras i systemet vilket i sin tur medför att man måste tänka på prestanda när det gäller svarstider. En person som arbetar med en analys tappar lätt bort sig om han eller hon måste vänta länge på att få fram resultaten. Normaliserade databaser kan innebära längre svarstider eftersom sammanslagning av tabeller kan behövas. För att få ner svarstiderna kan det bli aktuellt att denormalisera datastrukturen, alltså minska antalet tabeller. På detta sätt kan antalet sammanslagningar av tabeller minska vilket ger bättre prestanda på svarstider. De karaktäristiska dragen för ett system avsett för analyser är: • • • • • Flexibel datamodell för flexibla analyser. Denormaliserat för optimering av frågor. Innehåller stora datamängder, data som sträcker över flera år. Sammanför heterogen data till en plats vilket möjliggör analyser av den. Statisk data som ej ändras av användaren. Detta system är kort sagt ett system där data är anpassat för att presenteras och analyseras, jämfört med ett affärssystemet där informationen registreras. På grund av dessa skillnader mellan de behov som finns av analyser och den datastruktur där data ligger lagrat så behövs datavaruhusen. En ytterligare anledning till att placera data för analyser i ett annat system är för att minska påfrestningarna på affärssystemen. En analys av data över flera år skapar en fråga mot databasen som kan ta lång tid att beräkna och detta kan göra att affärssystemens prestanda sänks, vilket i de flesta fall inte är önskvärt. 6 ETL-verktyg för datavaruhus Under de senaste åren har idéerna kring datavaruhus förändrats. I den ursprungliga idén menade man att data i ett datavaruhus var statisk och inte gick att ändra när den väl var där. Gupta [Gupta 1997] menar att det är näst intill omöjligt att underhålla dynamisk data i ett datavaruhus och att alla data måste vara statisk. Detta är något man frångått på senare år och flera bl a Kimball [Kimball 1998] menar att ett datavaruhus måste kunna uppdateras. Om en leverantör t ex byter adress så måste denna förändring även slå igenom i datavaruhuset, vilket kan te sig ganska naturligt. 2.2.2 Dimensionella databaser Dimensionella databaserna, även kallade OLAP-databaser (On-line Analysis Processing), har med tiden blivit populär för att lagra data i ett datavaruhus. OLAP definierades i tolv punkter av E.F Codd 1993, och 1995 kompletterade han dem med ytterligare sex punkter [Pendse 2001]. Anledningen till OLAPdatabasens popularitet är att den ger användaren en intuitiv bild av hur data är organiserat, vilket underlättar analyser av data. Databasen ger även god prestanda när det gäller svarstider för frågor mot datan jämfört med en normaliserad relationsdatabas. Logiskt brukar OLAP-databaser representeras med hjälp av sk OLAP-kuber. En geometrisk kub har tre dimensioner, men en OLAP-kub kan ha fler. Nedan ser vi ett exempel på en OLAP-kub för ett bilföretag med tre dimensioner som p g a att den just består av tre dimensioner kan representeras med en geometrisk kub. Bild 1: Exempel på OLAP-kub. 7 ETL-verktyg för datavaruhus Dimensioner och fakta är två viktiga begrepp när vi talar om OLAP-kuber. Fakta är själva datan vi vill analysera och dimensionerna, axlarna i kuben, är de sätt vi vill analysera datan på. OLAP-kuben är indelad i celler där datan (fakta) ligger lagrad, som i detta fall är antal sålda bilar. Dimensionerna i kuben motsvarar de olika grupperingssätten som datan kan grupperas och summeras efter. Kuben ovan är tänkt att analysera bilförsäljningen i antal bilar över tidsperioden januari till mars 2001. Bilföretaget säljer tre bilmodeller (A, B och C) i tre affärer (Stockholm, Göteborg och Umeå). Bilmodeller och försäljningsort (affär) anses som lämpliga grupperingar och passar därför som dimensioner. En tredje dimension som är med i denna kub är tid. Tiden anger när bilarna såldes och ger möjlighet att gruppera bilförsäljningen tidsmässigt. Dessa tre dimensioner ger möjlighet att gruppera och summera datan i cellerna och de kan kombineras för önskad analys. Det totala antalet bilar som sålts under det första kvartalet 2001 är summan av alla celler vilket är 315 st (80+50+100+75+10). Utifrån denna totalsumma kan vi arbeta oss ner till en mer detaljerad nivå genom att gruppera kuben med hjälp av de olika dimensioner. Man kan se det som att man skär ut ett snitt ur kuben och får på det viset informationen grupperad efter dimensionen. Om vi t ex analyserar datan med hjälp av modelldimensionen ser vi att för modell B, som är en medlem i modelldimensionen, är summan av cellerna i det snittet 205 st (80+50+75). Modell B har alltså sålts i 205 exemplar under det första kvartalet 2001. Om vi fortsätter att skära ut delar ur kuben kan vi erhålla ännu mer detaljerad information. Vi lägger till affärsdimensionen och tittar bara på värden tillhörande dimensionsmedlemmen Umeå, alltså bilar av modell B som sålts i Umeå under det första kvartalet 2001, och ser att antalet blir 125 st (50+75). På detta sätt kan vi ställa komplicerade frågor till databasen och samtidigt ha en enkel och lättförståelig bild av databasen. Antalet celler som ingår i OLAP-kuben beror på hur dimensionerna är uppbyggda. Detta styr med vilken detaljrikedom fakta i kuben är lagrad. En dimension kan vara uppbyggd enligt en hierarki vars lägsta nivå bestämmer detaljrikedomen. En typisk dimension med hierarki är tidsdimensionen. Bild 2: Exempel på dimension för tid med hierarki. 8 ETL-verktyg för datavaruhus Ett exempel på en tidsdimension med hierarki ses på bild 2 (denna hierarki syns ej i OLAP-kuben på bild 1). Hierarkin i denna dimension är i fallande ordning, alla, år, kvartal, och månad, vilket gör att den mest detaljerade nivån av fakta i kuben är månadsvis. För varje nivå kan datan summeras och beräknas i förhand vilket minskar svarstider för databasen. Dessa delsummeringar kallas för aggregat [Lupin 2001]. Den översta nivån, alla, består av en medlem som summerar all data i kuben. Analyseras kuben med tidsdimensionen på nivå alla erhålls en summa av all data i kuben. Nästa nivå, år, består av tre medlemmar, vilka representerar tre olika år. Datan i kuben kan högst tillhöra en medlem (år) och detta medför att fakta i kuben delas upp på dessa tre medlemmar. Ett exempel på tre medlemmar för nivån år kan vara 1999, 2000 och 2001, och väljer vi 1999 får vi de värden i kuben som tillhör 1999 summerade. Genom att gå ner genom en hierarki på detta sätt får vi mer och mer detaljerad information om datan i kuben. Att röra sig ner i en dimensionshierarki och på det sättet få mer detaljerad information kallas för att göra ”drill-down”. Hierarkier i dimensioner kan byggas upp på olika sätt. En hierarki kan ha en eller flera rötter och kan vara balanserad eller obalanserad [Thomsen 1999]. Valet av struktur på hierarkin avgörs av hur dimensionen är uppbyggd i ”verkligheten”. 2.2.3 Stjärnmodellen Det fysiska lagringssättet för en OLAP-databas håller fast vid relationsdatabaser, men med restriktionen att fakta organiseras och grupperas med hjälp av olika dimensioner. Fakta lagras i faktatabeller medan dimensioner definieras med dimensionstabeller och de samordnas i vad man brukar kalla en stjärnmodell. En stjärnmodell består av en faktatabell och en mängd dimensionstabeller. Bild 3: Stjärnmodell I faktatabellen ligger förutom själva värdet (fakta) också referenser till de dimensionstabeller som definierar värdet. De dimensionstabeller som refereras 9 ETL-verktyg för datavaruhus från faktatabellen ger tillsammans varje värde en betydelse och dessa referenser utgör även den unika nyckeln för varje värde. Referenserna till dimensionstabellerna utgör alltså tillsammans primärnyckeln i faktatabellen. Primärnyckeln är det eller de attribut som unikt identifierar en tupel i databastabell. De värden som är lämpligast som fakta i en faktatabell är numeriska värden eftersom de går att addera. Det gör det möjligt att gruppera värden efter dimensionerna och på det sättet beräkna summor och medelvärden etc. Textdata lämpar sig inte eftersom det saknar denna egenskap. En dimensionstabell innehåller information om dimensionen och har en primärnyckel som unikt identifierar varje dimensionsmedlem (tupel). Övriga attribut i dimensionstabellen innehåller information om dimensionen och kan användas för att bygga upp hierarkier i dimensionen. Bild 4: Stjärnmodell för försäljningen för bilföretag. Bild 4 visar hur en stjärnmodell för OLAP-kuben på bild 1 skulle kunna se ut. Fakta, antal sålda bilar, ligger lagrat i faktatabellens attribut ’Antal’ och för varje värde finns referenser till tillhörande dimensionstabeller. Dimensionstabellerna innehåller, utöver primärnyckel, attribut som gör det möjligt att bygga upp hierarkier. Affärsdimensionsen innehåller fem attribut som gör det möjligt att geografiskt placera försäljningen på olika nivåer. En variant på stjärnmodellen är den så kallade snöflingemodellen (engelska: snowflake model). Denna modell bygger på stjärnmodellen, men minst en dimension har en tillhörande yttre dimension. Genom att använda sig av denna modell minskas dubbellagringen som uppkommer med hierarkier, men antalet sammanslagningar av tabeller ökar vid frågor med denna dimension [Kimball 1998]. 10 ETL-verktyg för datavaruhus 2.2.4 Dataflödet Nu när vi vet vad ett datavaruhus är och hur data är lagrat där så är det dags att titta på den miljö där datavaruhuset finns och hur data flödar från källa till slutanvändare. Nedan ser vi en enkel bild över hur data flödar genom ett system. Bild 5: Dataflöde från källor till datavaruhus och användarprogram. Informationen vi vill analyser finns lagrad i en eller flera datakällor. Dessa datakällor kan vara allt från enkla textfiler till mer komplicerade affärssystem. En typ av affärssystem som blir allt vanligare är sk ERP-system (Enterprise Resource Planning). ERP-system är affärssystem som bygger på en klientserver-lösning [Cox III, 1995] och de kan innehålla tusentals databastabeller. Exempel på ERP-system är SAP och BaaN. Andra typer av källor där informationen kan vara lagrad är databaser, kalkylark, e-post och Internetsidor. För att kunna sammanföra informationen från alla källor måste den ofta bearbetas. Den måste först extraheras ur källorna och sedan rensas och tvättas på olika sätt för att enkelt gå att analysera. Ett mellansteg där datan ligger efter extrahering kallas behandlingsarea (engelska: Staging Area). Det är här det mesta av transformeringen äger rum. Innan den laddas till datavaruhuset måste den omstruktureras så att den passar den struktur som används där, t ex en OLAP-databas. Denna process brukar delas in i tre steg och kallas för ETL (Extraction, Transformation, Loading) och program som sköter denna process kallas för ETL-verktyg. ETL behandlas i nästa kapitel ETL. När data är färdigbehandlat hamnar det så småningom i datavaruhuset. Datavaruhus brukar vara logiskt strukturerade efter de olika affärsområden som ingår i datavaruhuset. Ett sådan logiskt affärsområde kallas i datavaruhuset för ett data mart och kan t ex innehålla data från ekonomi- eller försäljningsavdelningen [Kimball 1998]. Viss data kan dock ingå i flera olika logiska affärsområden, det kan handla om information som är generell för hela företaget såsom personalinformation. Det sista steget i dataflödet är när informationen görs tillgänglig för användare. Användarna är personer som skall analysera informationen i datavaruhuset och de kan vara chefer och beslutsfattare. Dessa personer använder sig av olika program för att titta på och analysera informationen i datavaruhuset. Det finns en mängd olika applikationer för dessa ändamål, bl a rapportgeneratorer, OLAP-verktyg och data mining-verktyg. 11 ETL-verktyg för datavaruhus 2.3 ETL ETL är den processen som innefattar flyttning av data från källor till datavaruhus. Oftast är detta ingen enkel kopiering, utan omstrukturering och justering av data måste göras vilket gör att detta inte är någon liten och enkel uppgift. Upptill 70 procent av tiden i ett datavaruhusprojekt kan gå åt till ETL [Meyer 2001], och det är vanligt att företag avsätter mellan 40 till 70 procent av projektbudgeten till ETL [Allison 2001]. Dessa siffror säger en del om hur stor och viktig del ETL är i ett datavaruhusprojekt. I detta kapitel beskrivs ETL-processen, laddningen av datavaruhuset. Vilket ansvar har ETL, vad utförs av ETL och hur kan en ETL-lösning se ut? Detta är frågor som kommer att besvaras i kapitlet. 2.3.1 ETLs uppgifter ETL, som är en förkortning för de engelska orden Extraction, Transformation, Loading, kan sägas ha tre huvuduppgifter. Dessa går, inte helt oväntat, att utläsa ur själva förkortning ETL. • • • Läsning av data (Extraction) Omvandling av data (Transformation) Laddning av data (Loading) Dessa punkter är de tre faser eller steg som datan måste gå igenom för att införas i datavaruhuset. Det första steget är läsning av data från källorna där datan finns lagrad. Data kopieras i detta steg från källorna till en behandlingsarea. Behandlingsarean kan vara någon typ av databas eller en enkel textfil. När källdatan finns samlad i denna behandlingsarea kan nästa steg påbörjas, transformering av data. Under denna transformering tvättas, rensas och omstruktureras data på ett sätt att det senare kan laddas in i datavaruhuset. Exempel på tvättning är avrundning av tal och exempel på rensning är att man helt enkelt plockar bort data som inte är intressant för någon analys. Omstrukturering av data behövs när strukturen på data skiljer sig mellan källan och datavaruhuset. Detta förekommer t ex när källan är en relationsdatabas och datavaruhuset bygger på en OLAP-databas. När transformeringen är avklarad kan det sista steget inledas, själva laddningen av data till datavaruhuset. 12 ETL-verktyg för datavaruhus Bild 6: ETL-processens tre steg. Denna modell av laddningen av ett datavaruhus används av bl a Kimball [Kimball 1998] och Scott [Scott 2000]. Det är viktigt att förstå att dessa tre steg inte alltid är distinkta från varandra. Kimball [Kimball 1998] understryker att transformeringen av data kan ske i processens alla tre steg. Redan under extraheringen av källdata kan data omvandlas under extraktrutinerna och detta gäller även för laddningsrutinerna. 2.3.2 Faktorer som påverkar ETL Den miljö där ETL arbetar påverkar utformningen av ETL-processen [Scott 2000]. De faktorer som påverkar ETL-processen kan delas in i fyra huvudkategorier: • • • • Data och datastruktur Applikationer Arkitektur Personal 2.3.2.1 Data och datastrukturer Det första man kanske kommer att tänka på som påverkar laddningen av ett datavaruhus är själv datan som skall laddas och hur dess struktur ser ut. Kvaliteten på datan bestämmer vad som måste göras med den under transformeringen. Idealet är att datan i datakällorna är så pass bra att den bara är att ladda in, men så är sällan fallet. Om t ex inmatningen av textsträngar görs manuellt i ett affärssystem kan detta medföra problem vid tolkningen av dessa. Två olika strängar kan egentligen betyda samma sak, som t ex ”I.B.M” är samma företag som ”IBM”, och detta måste ETL-processen klara av att hantera. ETL ansvarar alltså för att höja kvaliteten på datan så att analyser blir möjliga. Andra typer av dataomvandlingar är datatypskonvertering och tolkning av förkortningar och nullvärden. Förkortningar som används i datakällan för att spara utrymme lämpar sig inte för analyser. Om t ex en bit används för att representera ja och nej för ett attribut i datakällan, är det bättre att använda sig av textsträngen ”ja” eller ”nej” för detta attribut i datavaruhuset för att öka förståelsen vid analyser. ETL-processen ansvarar för att detta görs. 13 ETL-verktyg för datavaruhus I de fall där källdata och datavaruhusets datastruktur skiljer sig måste data omstruktueras. Detta blir aktuellt när data ligger lagrat enligt en relationsmodell och datavaruhuset använder sig av en OLAP-databas. Generellt kan man säga att ju mer datastrukturerna skiljer sig från varandra desto mer krävs av ETL för att anpassa datan innan den kan laddas. När data laddas från flera olika datakällor kan problem uppkomma med primärnycklarna som finns i dessa källor. Primärnycklarna i de olika källorna kan stå i konflikt med varandra vilket medför att datan inte kan sammanföras i datavaruhuset. Spänner laddningen över lång tid finns det risk att återanvändning av primärnycklar sker i datakällorna. Eftersom affärssystem i vissa fall rensas så finns risk att primärnycklar återanvänds, och detta skapar ytterligare problem för datavaruhuset. En lösning som bl a förordas av Kimball [Kimball 1998] och Navarro [Navarro 2000] är att istället för datakällornas primärnycklar använda en annan nyckel i datavaruhuset. Denna nyckel kallas för surrogatnyckel och kan vara uppbyggd på olika sätt. Det som rekommenderas är att använda ett löpnummer (heltal) för varje tupel och detta är även fördelaktigt för utrymmesbesparingar. Ett heltal tar fyra byte jämfört med en textsträng som kan ta betydligt mer utrymme. Fördelen med att använda surrogatnycklar istället för källsystemens primärnycklar kan sammanfattas med följande punkter: • • • • Förenklar sammanföring av data från olika system som använder olika typer av primärnycklar. Förebygger problem med återanvändning av primärnycklar i datakällorna. Förenklar eventuellt byte av källa, då källans primärnycklarna inte påverkar datavaruhuset. Kräver mindre lagringsutrymme. Nackdelen med att använda surrogatnycklar i datavaruhus är att det blir mer kompilicerat att införa och uppdatera data. När dessa operationer ska utföras måste källdatans primärnyckel samman kopplas med datavaruhusets motsvarande surrogatnyckel innan operationen kan verkställas. Hanteringen av dessa surrogatnycklar faller på ETL-processens ansvar. 2.3.2.2 Applikationer Utöver de tre huvudsakliga uppgifterna som ETL-processen har tillkommer andra uppgifter, såsom loggning av felaktigt data och underrättelse av fel. Om dessa uppgifter ska skötas av redan befintliga program måste ETL-processen klara av att kommunicera med dessa. ETL-processen måste passa in bland de applikationer som företaget redan använder sig av och dessa faktorer påverkar givetvis utformningen av ETL-processen. 2.3.2.3 Arkitektur Även faktorer som kommer från den dataarkitektur företaget använder sig av påverkar ETL. Det kan handla om kommunikation och överföring av data över ett nätverk mellan två olika typer av plattformar, t ex Windows och UNIX. Ligger data utspritt på flera olika plattformar måste ETL-processen klara av att kommunicera och hämta data från dessa. Andra faktorer som påverkar ETL kan vara vilken tillgång på lagringsutrymme ETL-processen har, för exempelvis behandlingsarean. 14 ETL-verktyg för datavaruhus 2.3.2.4 Personal Personalens kunskap och bakgrund påverkar utformningen av ETL. Utvecklas ETL-processen av en grupp programmerare som är experter på ett programmeringsspråk väljer de nog det språket även fast det kanske inte är den optimala lösningen. Samtidigt är det bra om kompetensen för lösningen av ETL-processen finns i företaget. Personalen som ska administrera ETLprocessen har förmodligen också en del att säga om hur driften i form av loggning och felhantering ska ske. 2.3.3 Angreppssätt för ETL Hur kan man nu praktiskt lösa denna ETL-process? Vi har ett problem vi vill lösa med hjälp av en dator och ställs då inför två alternativ, skriva ett program eller köpa ett program som löser detta problem. Scott [Scott 2000] menar att det finns fyra olika angreppsätt för dataomvandling och dataöverföring. Dessa är att programmera en egen lösningen, köpa en kompilator för meta data, köpa ett ETL-verktyg eller välja en blandning av de tre. Jag vill dock ge följande bild av de alternativ som finns: 1. Programmera en egen lösning. 2. Köpa ett ETL-verktyg. 3. Välja en blandning av de två ovannämnda. Anledningen till att jag väljer denna indelning istället för Scotts är att jag anser att hans kategorier ”går in i varandra”. Jag nöjer mig med att säga att det går att programmera en lösning (program, kompilator), köpa ett ETL-verktyg (program, kompilator) eller kombinera dessa två. 2.3.3.1 Programmera en egen lösning Att programmera en egen lösning kan göras på olika abstraktionsnivåer. Man kan använda sig av SQL, skriva ett program i något programmeringsspråk (C++, Java, etc), eller skriva en egen kompilator som utifrån Meta Data från källor och datavaruhus skapar ETL-processer. Eftersom denna typ av ETLlösning ligger relativt nära hårdvaran har man goda möjligheter att optimera den efter sin situation, men samtidigt så medför den en risk. Risken är att kompetensen för programmet ligger hos en eller ett fåtal personer, de personer som var med och utvecklade programmet. Försvinner de från företaget så försvinner även kompetensen för programmet. Risk finns även för att vidareutveckling och underhåll av egenutvecklade lösningar är svårt och kostsamt. 2.3.3.2 Köpa ett ETL-verktyg Istället för att skriva en egen lösning kan man köpa en ETL-lösning. Program som jobbar med laddning av datavaruhus brukar kallas för ETL-verktyg och de finns enligt Meyer [Meyer 2001] över 75 produkter som påstår sig ha någon slags ETL-funktion. Fördelen med denna lösning är att man får en produkt som troligen har flera användare vilket ökar möjligheten till externt kunnande om produkten. Några av nackdelarna är att man får en produkt som är generell och inte optimerad för sin situation, och att produktens funktionalitet och möjligheter styr strukturen på data i datavaruhuset [Kimball 1998]. 15 ETL-verktyg för datavaruhus 2.3.3.3 Välja en blandning av de två ovannämnda alternativen Ett alternativ är att välja en lösning som innehåller de två ovannämnda angreppssätten. Det kan t ex finnas situationer där ett köpt verktyg inte klarar av en viss typ av omvandling och denna funktion måste implementeras i en egen delapplikation. Detta gör då att man kompletterar det köpta ETLverktyget med ett eget program. Ställs man inför detta problem ofta med ett köpt ETL-verktyg bör man nog fundera på om ETL-verktyget är värt att ha eller om man ska programmera en egen lösning. Det angreppsätt som är aktuellt i detta examensarbete är förstås att köpa ett ETL-verktyg, eftersom arbetet består av en jämförelse av två sådana produkter. Anledning till att ABB väljer att köpa ett ETL-verktyg är för att man eftersträvar en allmän lösning där extern support kan erhållas. Att köpa en produkt anses också vara mer lätthanterligt och enklare att underhålla än en unikt tillverkad lösning. 2.4 Jämförelsemetod Hur jämför man två ETL-verktyg? Ett sätt kan ju vara att gå igenom varje produkt i detalj och se vilka funktioner och möjligheter varje produkt besitter. Problemet med denna metod är att den tar mycket tid, särskilt om produkten är stor. Ett annat problem med denna metod är att den ger information om produkten som inte är relevant för att lösa problemet. Resultat man får från en sådan undersökning täcker förmodligen områden som inte är aktuella för det datavaruhus man utvecklar. Dessutom finns ju denna information redan i tillverkarnas dokumentation av produkterna och kan alltså hämtas där. Jag letade ett tag efter en metod för att göra jämförelser av ETL-verktyg, men hittade inget konkret tillvägagångssätt. Det jag dock hittade var andras jämförelser av ETL-verktyg, problemet med dessa var att få tillgång till resultaten kostade mycket pengar. Tillslut bestämde jag mig för att utveckla en egen jämförelsemetod. Varför gjorde jag nu detta? Jo, tittar man på de fyra faktorer som påverkar utformningen av ETL, data, arkitektur, personal, och applikationer, så är de unika för varje datavaruhus. Data som laddas kommer från företagets egna källor, arkitekturen och applikationer har företaget byggt upp själv och de behov som personalen har är också olika från fall till fall. Jag har därför byggt upp min jämförelsemetod av ETL-verktyg efter de behov och förutsättningar som finns på ABB. Ett problem med denna metod är att den fokuserar på nuet. Den ser inte till framtida behov som kan finnas på datavaruhuset och ETL-verktyget. För att ta hänsyn till tänkbara framtid behov, så har jag utgått från andras erfarenheter av val och behov av ETLverktyg. Jag har främst studerat skrifter av Kimball [Kimball 1998] och Meyer [Meyer 2001] som belyser viktiga egenskaper hos ETL-verktyg. Det är viktigt att komma ihåg att detta inte är någon jämförelse mellan verktygen som ger svar på vilket verktyg som passar bäst i ett generellt fall. Jämförelsen syftat till att avgöra vilket verktyg som är mest lämpligt för ABBs situation och förutsättningar. Nedan följer en beskrivning av tillvägagångssättet för jämförelsen av ETLverktygen. 1. Identifiera behov, direkt eller allmänt behov. 2. Definiera parametrar som gör det möjligt att mäta hur produkten uppfyller behoven. 16 ETL-verktyg för datavaruhus 3. Vikta parametrar. 4. Gruppera parametrarna i huvudgrupper. Alla parametrar som tillhör en huvudgrupp kommer att påverka gruppens resultat beroende på dess vikt. En parameter med låg vikt påverkar gruppens sammanlagda resultat lite, medan en parameter med hög vikt påverkar resultatet mycket. 5. Skapa ett betygssystem där det är enkelt att betygsätta varje parameter. 6. Studera varje produkt och betygsätt varje parameter 7. Summera varje grupp av parametrar och normalisera värdet. 8. Jämför produkternas resultat. 2.4.1 Identifiera behov Det första steget är ganska naturligt och det är att identifiera vilka behov och krav som finns på ETL-verktyget. Det är dels krav som ställs direkt på ETLverktyget, såsom datastrukturer i källorna och administrering, och dels kravs som ställs på rapport- och analysmöjligheter som i sin tur påverkar ETLverktyget. De krav som ställs direkt på ETL-verktyget kommer från ABBs ITavdelning, de som ska sköta och utveckla laddningarna. Kraven härifrån var ganska konkreta. Inköpsavdelningen, som är kunden i detta projekt, hade några önskningar om vad rapporter skulle innehålla och klara av, men kraven på analysmöjligheter var inte lika klara. Vidareutveckling av datavaruhuset kan medföra andra behov och krav på ETLverktyget än de som kan identifieras enligt ovan. Därför har jag inkluderat behov som med hög sannolikhet kan tänkas uppkomma i framtida versioner av datavaruhuset. Dessa behov grundas på mina studier av datavaruhus och ETLverktyg. De olika typerna av behoven jag har identifierat efter detta resonemang är följande. • • Direkta behov. Dessa behov kan direkt utläsas från de krav och behov som kommer från IT- och inköpsavdelningen. Dessa behov finns idag. Allmänna behov. Dessa behov kan ej utläsas från de krav och behov som identifierats, men bör ändå tillgodoses av ETL-verktyget. Härkomsten av dessa behov kommer ifrån mina studier av datavaruhus och ETL-verktyg. 2.4.2 Definiera och vikta parametrar Utifrån de behov som identifierats skapas parametrar som möjliggör en jämförelse av verktygen. En parameter kan innefatta ett eller flera behov och varje parameter viktas mellan ett till tre, där ett innebär att behoven parametern innefattar är av mindre betydelse och tre innebär att behoven parametern innefattar är av högre betydelse. Viktningsnivåerna beskrivs enligt följande: 1. Låg. De behov som en parameter med denna vikt beskriver uppskattas om de uppfylls av ETL-verktyget. Behov av detta slag finns troligen inte idag, men kan tänkas uppkomma i framtida versioner av datavaruhuset. 2. Medel. De behov som en parameter med denna vikt beskriver bör uppfyllas av ETL-verktyget. Behov av detta slag finns troligen idag eller kommer med hög sannolikhet att uppkomma vid en vidareutveckling av datavaruhuset. 3. Hög. De behov som en parameter med denna vikt beskriver måste uppfyllas av ETL-verktyget. Behov av detta slag finns idag. 17 ETL-verktyg för datavaruhus Alla direkt behov får automatiskt vikten tre, dessa behov måste ju uppfyllas. Allmänna behov får däremot vikten två eller vikten ett. Skillnaden mellan vikt två och ett är att en parameter med vikt två beskriver ett behov som kan uppkomma med hög sannolikhet, medan vikt ett beskriver ett behov vars sannolika uppkomst anses vara låg. Behov Direkta behov Viktning 3. Måste 2. Bör Allmänna behov 1. Uppskattas Bild 7: Samband mellan behov och viktning av parametrar. 2.4.3 Gruppering av parameter För att enklare jämföra verktygen valde jag att gruppera parametrarna efter olika behovsområden. Få grupperade jämförelsevärden är lättare att överblicka än många, men det är samtidigt viktigt att komma ihåg att lyfta fram stora avvikelser som kan styra resultatet i en någon riktning. 2.4.4 Betygssystem När det som ska mätas hos verktygen är definierat gäller det att utveckla något sätt att bedöma hur väl verktyget uppfyller behovet. Jag bestämde mig för en fyragradig betygsskala som jag tillämpade på parametrarna för varje verktyg. Betyg 3 är högsta betyg och betyg 0 är sämsta. • • • • 3 Bra. Verktyget har den funktionalitet eller egenskap som efterfrågas. 2 Mindre bra. Verktyget har den funktionalitet eller egenskap som efterfrågas, men verktygets sätt att bemöta behovet komplicerar lösningen. Funktionaliteten eller egenskapen ligger dock fortfarande inom ETLverktyget. 1 Dåligt. Verktyget saknar efterfrågad funktionalitet eller egenskap. Avsaknaden medför att en lösning måste göras med hjälp av extern programmering, programmering som ligger utanför ETL-verktyget. 0 Saknas. Verktyget saknar efterfrågad funktionalitet eller egenskap. Hur mycket en parameter påverkar resultat för ETL-verktyget beror på parameterns vikt och verktygets betyg för denna parameter. Parameterns vikt multipliceras med verktygets betyg och produkten blir verktygets resultat för denna parameter. För vissa parametrar passar inte beskrivningen av betygen ovan. Detta gäller parametrar som inte bedömer verktygets funktionalitet, såsom dokumentation och support. Om t ex dokumentationen av ett verktyg uppfattas som dålig får 18 ETL-verktyg för datavaruhus den således betyg ett, utan att det innebär att det går att lösa med extern programmering. 2.4.5 Beräkning av parametergrupps betyg Varje parametergrupps gemensamma betyg baseras på de ingående parametrarnas betyg. För att underlätta jämförelsen och göra resultat oberoende av antal ingående parametrar så normaliserade jag parametergruppens betyg enligt följande formel: Gruppbetyg = (b1 * v1) + (b 2 * v 2) + ... + (bn * vn) 3 * (v1 + v 2 + ... + vn) där bi är betyget verktyget fått för parameter i, 1 ≤ i ≤ n, n är antal parametrar som ingår i gruppen och vikten på parameter i är vi. 2.4.6 Analys av jämförelsemetoden Hur förhåller sig parametrar med olika vikt mellan varandra och hur mycket påverkar de gruppens resultat där de ingår? Procentuellt sätt förhåller sig parametrarna till varandra enligt tabell 1. Vikt 3 2 1 Procentuell ökning från underliggande vikt 50 % 100 % - Tabell 1: Procentuell ökning i betydelse mellan vikter. Vi ser i tabell 1 att betyg tre och två ligger procentuellt sett närmare varandra än betyg två och ett. En parameter med vikt två påverkar resultat för parametergruppen dubbelt så mycket (100%) än vad en parameter med vikt ett gör, medan en parameter med vikt tre påverkar resultat endast hälften (50%) så mycket som vad en parameter med vikt två gör. Detta medför att skillnaden i betydelse mellan parametrar med vikt tre och två är mindre än skillnaden mellan parametrar med vikt två och ett. Anledningen till att skillnaden mellan parametrar med vikt tre och två är mindre är för att parametrar med vikt två representerar ett behov som förmodligen redan finns idag och därför bör ha hög betydelse. Alltså blir parametrar med vikt två 100% mer betydelsefulla än parametrar med vikt ett, men parametrar med vikt tre blir bara 50% mer betydelsefulla än parametrar med vikt två. 19 ETL-verktyg för datavaruhus Beräkning av betyg 10 8 vikt 1 6 vikt 2 4 vikt 3 2 0 noll ett två tre betyg Bild 8: Förhållande mellan viktning och betyg. Hur många parametrar som ingår i en grupp påverkar gruppens resultat. Ju fler parametrar man har i en och samma grupp desto mindre påverkar varje enskild parameter gruppens totala betyg. Därför är det viktigt att tänka på att balansera grupperna så att styrkor och svagheter hos produkten kommer fram. Skapar man en parametergrupp med många parametrar kan det vara idé att dela på denna för att kritiska parametrar ska påverka mer. Parametergrupperna bör för övrigt innehålla parametrar som mäter funktioner och egenskaper inom samma problemområde, t ex laddningsrutiner och administration, för att ge ett användbart mätvärde. Hur slår nu denna jämförelse mellan olika ETL-verktyg? Kan man efter att ha beräknat fram de olika gruppbetygen välja det verktyg som har högst betyg? Svaret på den frågan är nej. Anledningen till detta beskrivs enklast med ett exempel. Antag att vi har gjort en jämförelse mellan tre ETL-verktyg (A, B och C) och använt oss av metoden ovan. Vi nöjer oss med att ha en parametergrupp med tre parametrar (a, b och c) för enkelhetens skull. Så här kan resultat tänkas se ut efter studien av verktygen är avklarad: Betyg för ETL-verktyg Parameter vikt A B C a b c Grupp resultat 3 2 1 1 2 1 0 3 3 2 1 0 0,44 0,50 0,44 Tabell 2: Exempel på parametergrupp Använder vi formeln för att beräkna gruppresultatet ser vi att B får 0,50, som är bästa resultat och A och C ligger på delad andra plats på vardera 0,44. Skulle vi nu bara titta på dessa siffror och därmed välja verktyg B, så väljer vi ett 20 ETL-verktyg för datavaruhus verktyg som inte kan möta de aktuella behov som finns. Parameter a har nämligen vikt tre, vilket är ett direkt behov för lösningen, men verktyg B har fått betyg noll för den parametern. Verktyg B uppfyller alltså inte behoven som parameter a beskriver och vi kan därför inte använda verktyg B för att lösa de laddningsbehov som finns. Verktyg som får betyg noll på en parameter med vikt tre måste därför tas bort eftersom de inte kan uppfylla de direkta behov som finns. Verktyg A och C som fått samma resultat, men de skiljer sig åt. Det man kan säga om verktyg A är att det är en bred produkt med stöd för troliga behov eftersom verktyget har fått bra betyg på parametrar för allmänna behov. Verktyget A uppfyller dock inte de direkta behoven i sig självt, men det gör verktyg C som fått betyg två på denna parameter. Verktyg C är dock sämre på allmänna behov som kan tänkas uppkomma senare. Vilken produkt man väljer av dessa beror på om man tänker långsiktigt och då väljer verktyg A, eller kortsiktigt och då väljer verktyg C. 2.4.7 Risker med jämförelsemetoden Vilka risker och svagheter finns det nu med denna jämförelsemetod? De risker jag har identifierat är: 1. Val av felaktiga parametrar. En risk är att man väljer fel mätparametrar och helt enkelt undersöker fel egenskaper i verktygen. Detta medför att valet av verktyget görs på felaktiga grunder. 2. Felaktig viktning av parametrar. Ytterligare en risk med jämförelsemetoden är att vikten av parametrar uppskattas felaktig vilket leder till att parametern påverkar resultatet för mycket eller för lite. Saknar man kunskap om den aktuella situationen där datavaruhuset ska implementeras eller kunskap om hur källdata ser ut kan parametrarnas vikt bli fel. 3. Felaktig bedömning av parametrar. Eftersom verktygen jämförs teoretiskt finns det risk att de källor som används för att erhålla informationen ej är korrekt och därför ger en felaktig bedömning. Det bästa sättet att jämföra två saker är förstås att ha tillgång till och använda det man jämför, men det var inte möjligt i detta fall. Det som stämmer i teorin kanske inte fungerar i praktiken. Hur undviker man dessa risker när man utför jämförelsen? Det hela handlar om att vara väl insatt i problemet och ämnesområdet. Är man inte det finns risk att man väljer fel parametrar och inte inser vikten av de parametrar man väljer. För att minska risken för detta så inledde jag examensarbetet med att studera datavaruhus, ETL och de behov som fanns lokalt på ABB. Risken för felbedömning av verktygen vid en teoretisk studie kan vara svår att undvika, men jag har försökt undersöka verktygen så korrekt som möjligt utifrån tillverkarnas dokumentation. Detta är en risk man får leva med vid en teoretisk jämförelse. Denna jämförelsemetod är generell och valet av parametrar gör den specifik för produkter och behov. Det är alltså tänkbart att metoden kan användas inom andra områden än jämförelser av ETL-verktyg. 21 ETL-verktyg för datavaruhus 3 Analys av ETL-verktyg I detta kapitel går vi ner på den faktiska nivån i jämförelsen. Jag börjar med att titta på vilka förutsättningar som finns på ABB, den miljö där ETL-verktyget ska arbeta. Efter denna nulägesanalys, så är det dags att presentera vilka parametrar som skall användas för jämförelsen och varför de valdes. När valen av parametrarna är gjorda så beskriver jag hur ETL-verktygen svara på dessa parametrar. Avslutningsvis sammanfattas verktygens resultat och en slutsats om vilket verktyg som ska väljas kan dras. 3.1 Nulägesanalys för ABB Sedan 1994 har ABB använts sig av ERP-systemet BaaN IV. BaaN används i många delar av verksamheten, bl a order, projektstyrning och finans. I nuläget är det tänkt att datavaruhuset ska hämta all sin data från BaaN. BaaN lagrar sin data i en underliggande Oracle-databas. Det finns även andra system som i en framtid kan tänkas leverera data till datavaruhuset. ABB har tre egenutvecklade system, MSS, COSY, och OSM, som alla tre innehåller data som kan vara intressant för analys. MSS är ett offertsystem innehållande försäljningsinformation. Datan i detta system ligger lagrat i en Oracle-databas. COSY är ett kostnadskalkyleringsprogram som innehåller kalkyler. Här används en kombination av Microsoft Access och Oracle för att lagra data. Det tredje systemet, OSM, är ett huvudplaneringssystem vilket använder sig av Microsoft SQL Server 2000 för att lagra data. Utöver dessa system finns även data lagrat i Microsoft Excelfiler. Enligt tidigare beslut ska Microsoft SQL Server 2000 användas för att utveckla datavaruhuset. Microsoft SQL Server 2000 är i grunden en databashanterare som även innehåller en analysserver med OLAP-möjligheter. 3.2 Val av parametrar Vilka funktioner och egenskaper är intressant att titta på när man ska jämföra ETL-verktyg? Meyer [Meyer 2001] och Kimball [Kimball 1998] radar upp en mängd saker man bör undersöka vid ett val av ETL-verktyg och de tar i stort sätt upp samma saker. Meyer fokuserar på fem huvudkriterier som han anser är viktiga: • • • • • Komplexitet. Innefattar datakällors format och struktur och hur detta påverkar ETL. Samtidiga processer. Innefattar hur många samtidiga aktiviteter verktyget klarar av, såsom laddningar och utveckling av laddningar. Kontinuitet. Innefattar frågor om hur pass bra verktyget skalar och klarar oväntade händelser. Kostnad. De olika kostnader som uppkommer med verktyget. Överensstämmelse. Undersöker hur pass bra verktyget passar in i företagets nuvarande miljö. 22 ETL-verktyg för datavaruhus Kimball koncentrerar sig mer på transformationsrutiner för tvättning och omstrukturering av data. De kriterier jag valde kommer främst från dessa två källor, men även från intervjuer med min handledare (Tommy Jakobsen). Parametrar jag anser vara lämpliga i denna jämförelse har jag placerat in i fem huvudgrupper, parametergrupper. De fem parametergrupperna är följande: • • • • • Anslutningsmöjligheter Laddningsfunktionalitet Användarvänlighet Administration och drift Kostnader Totalt ingår 28 parametrar i dessa fem grupper. En sjätte grupp, referenser, som skulle belysa andras användande av produkterna var med från början. Tyvärr lyckades jag inte få tillgång till användbar information för denna grupp och därför uteblev den. Nedan beskrivs varje parameter och det behov som ligger till grund för parametern. Detta fungerar därför också som en kravspecifikation för ETLverktyget. Parameterns betydelse i ABBs datavaruhus framkommer av parameterns vikt och denna vikt har bestämts vid samtal med min handledare (Tommy Jakobsen). Varje parameter har ett nummer för att lättare referera till parametern. Den första siffran i numret säger vilken parametergrupp parametern tillhör och den andra siffran särskiljer parametrar inom samma grupp. 3.2.1 Anslutningsmöjligheter (grupp 1) Denna grupp av parametrar har tagits med för att undersöka vilket stöd verktyget har för anslutningar mot olika datakällor och datavaruhus. Ett stöd för anslutningar mot de aktuella enheterna är naturligtvis ett måste, men generellt sätt bör verktyget ha många anslutningsmöjligheter. Anledningen till detta är att täcka framtida behov av extraktion av data från system som inte används idag. Dessutom är det positivt om anslutningsmöjligheterna går att utöka i verktyget efterhand. Nya system och format på data utvecklas hela tiden, klarar då verktyget att möta dessa behov? De parametrar som ingår i denna grupp är följande: Aktuella enheter (1.1) Beskrivning: Denna parameter mäter verktygets sätt att bemöta de direkta behov av anslutningar som måste finnas för att ladda datavaruhuset. De enheter som i nuläget är aktuella är textfiler (ASCII) och MS SQL Server 2000. Direkta anslutningar mot BaaN har ej tagits med eftersom extraktskript skall användas för att erhålla data ur BaaN och dessa skript genererar textfiler. Dessa textfiler (extraktfiler) laddas sedan in i datavaruhuset och kan lätt laddas om vid fel. Vikt: Tre. Framtida enheter (1.2) Beskrivning: Här belyses verktygets möjlighet att ansluta sig till andra enheter än de som är av direkt behov. Ju fler enheter som kan anslutas desto bättre, men 23 ETL-verktyg för datavaruhus fokus ligger på de system som i dagsläget finns på ABB. Det handlar om Oracle, MS Access och MS Excel Vikt: Två. Utveckling (1.3) Beskrivning: Egen utveckling av fler anslutningsmöjligheter ökar flexibiliteten hos verktyget. Finns möjlighet till detta måste man inte förlita sig på att tillverkaren utvecklar och levererar de gränssnitt man är i behov av, utan ges möjligheten att själv utveckla gränssnitt mot data och applikationer. Denna parameter mäter de möjligheter som finns i verktyget att utveckla egna gränssnitt av denna typ. Vikt: Ett 3.2.2 Laddningsfunktionalitet (grupp 2) Verktygs funktionalitet för dataladdning är viktig eftersom den styr utformning av ett datavaruhus. Hög funktionalitet och flexibilitet i laddningsverktyget gör att laddning av data kan göras oavsett hur designen av datavaruhuset ser ut. Inbyggda funktioner som underlättar utvecklingen av ETL-verktyget är bra, men vikten av dessa inbyggda funktioner måste uppskattas. Ett dyrt verktyg med många inbyggda funktioner kan vara ett onödigt dyrt verktyg om dessa funktioner varken behövs eller används. Det som eftersträvas i denna grupp är att verktyget har lättanvända inbyggda funktioner som kan användas med en minimal programmeringsinsats. Nedan följer de nio parametrar som placerats i denna grupp. Sammanslagning av data (2.1) Beskrivning: För att data ska ge en meningsfull analys måste datan vara samstämmig, datan måste ligga på samma abstraktionsnivå, och inte vara summerad på olika nivåer. Det kan hända att data från två olika system ligger summerad på olika nivåer och för att möjliggöra en meningsfull analys måste datan summeras till samma nivå. I en sådan situation krävs att ETL-verktyget klarar av sammanslagning och summering av data. De funktioner som utför denna typ av databehandling brukar kallas för aggregat. Aggregat kan också användas för att höja prestanda på svarstiderna i datavaruhuset. Stora datamängder med hög detaljrikedom kan summeras för att minska datamängden och på så vis minska svarstiden på frågor. Det som eftersöks med denna parameter är att verktyget har en tydlig och enkel hantering av dessa aggregat. Vikt: Två. Surrogatnycklar (2.2) Beskrivning: Lagras datan enligt den dimensionella modellen i datavaruhuset är det också troligt att surrogatnycklar behövs. Hur bra ETL-verktyget hanterar dessa nycklar är därför viktigt. När en ny datapost laddas så tilldelas den en ny surrogatnyckel och när en datapost ska uppdateras måste kopplingen mellan källans primärnyckel och datavaruhusets surrogatnyckel kontrolleras. Hantering omfattas alltså av skapande och kontroller av surrogatnycklar. Kontroll av nycklar kan göras med hjälp av kontroller mot datakällor (se punkt 2.3 nedan). Vikt: Tre. Kontroll mot datakällor (2.3) Beskrivning: Denna parameter mäter verktygets funktionalitet att utföra kontroll av data (engelska: look-ups) mot andra lagringsplatser. Det kan handla om 24 ETL-verktyg för datavaruhus villkorssatser som styrs av om data finns i en databas eller inte, eller metoder för att erhålla värden från en extern datakälla. Behov av detta finns i hantering av surrogatnycklar för att kontrollera vilka surrogatnycklar som är använda och dessutom måste kontroll av inkommande data göras för att se om datan redan finns lagrad i datavaruhuset. Vikt: Tre. Stränghantering (2.4) Beskrivning: Hantering av textsträngar kan behövas för att få samstämmighet i textdata. Det kan vara så att formatet på samma textdata skiljer sig i systemet där data lagras och då måste verktyget kunna formatera om texten så att den överensstämmer och går att sammanfoga. Exempel på stränghantering är sammanlänkning av textsträngar och funktioner att plock ut delar av en textsträng. Exakt vilken typ av stränghantering som behövs är svårt att säga i förväg, men en grov uppskattning av vad verktyget klarar av kan ändå vägleda vid betygsättningen. Vikt: Två Tilldelning av grundvärden (2.5) Beskrivning: Om den extraherade datan som läses av verktyget inte är fullständig så kan det vara viktigt att fylla dessa luckor med lämpliga beskrivande värden. Anledningen till detta är att undvika att data går förlorad i analyser. Saknas referens till en dimensionstabell för en tupel i faktatabellen förloras detta fakta om datan analyseras med den dimension. Grundvärden kan också användas för att påvisa att luckor finns i datakällorna. ETL-verktyget bör kunna hantera tilldelning av grundvärden till felaktig eller saknad data. Vikt: Två Verifiering och dirigering av indata (2.6) Beskrivning: Att ha möjlighet att kontrollera rimligheten av indata innan laddningen är viktigt för att hålla god datakvalitet i datavaruhuset. Felaktig data beroende på den mänskliga faktorn förekommer i källdatan och dessa fel bör upptäckas av ETL-verktyget. Det kan t ex handla om orimliga leveransdatum eller orimliga valutakurser. Denna parameter avser att mäta verktygets funktionalitet för att bygga upp kontrollverk enligt affärsregler och efter dessa dirigera data. Speciella funktioner som förenklar denna verifiering och dirigering uppskattas. Vikt: Två. Konvertering av datatyper (2.7) Beskrivning: För att analyser av data ska vara möjliga krävs att data är lagrat med samma datatyp. Om data tankas från flera olika system kan data vara lagrat i olika datatyper och i dessa fall är det viktigt att möjlighet att konvertera data finns i ETL-verktyget för att kunna analysera informationen. Vikt: Två. Pre- och postanrop (2.8) Beskrivning: Denna funktionalitet syftar till att ge möjlighet att före och efter vissa steg i laddning och omvandling av data ge möjlighet till externa funktionsanrop. Anledningen till att denna parameter tas med är att denna funktion ökar flexibiliteten hos verktyget. Exempel på när detta kan vara användbart är om man behöver bygga upp en egen loggningsprocedur för laddningen. Då kan man med hjälp av denna funktion skriva ut händelser som 25 ETL-verktyg för datavaruhus inträffar vid olika tillfällen under laddning, före laddning börjar, för varje tupel och efter avslutad laddning. Vikt: Ett Skötsel av långsamt föränderliga dimensioner (2.9) Beskrivning: Om dimensionstabellerna i datavaruhuset uppdateras måste ETLverktyget klara av att hantera denna uppdatering. Dimensionstabeller som förändras sällan är en vanlig typ av dimensionstabell och de brukar kallas för långsamt föränderliga dimensioner. Hur uppdatering sker beror på om man är intresserad av att behålla tidigare värden eller om endast det nya värdet är intressant. Långsamt föränderliga dimensioner brukar indelas efter detta i tre olika kategorier, typer: 1. Den data som förändrats skrivs över och den gamla datan går förlorad. 2. Den nya datan lagras i en ny tupel med en ny surrogatnyckel. Den gamla datan förblir orörd och historiken sparas. 3. Skapa ett ”gammal” fält i tabellen som innehåller det senaste värdet på datan innan förändringen. Det gör att det föregående värdet lagras tills nästa förändring. Vad som finns inbyggt i verktyget för att underlätta skötsel för dessa dimensioner är intressant att undersöka. Vikt: Tre. 3.2.3 Användarvänlighet (grupp 3) Användarvänligheten är naturligtvis viktig för de som kommer att utveckla ETL-processer och sköta ETL-verktyget. Inbyggda grafiska verktyg för utveckling och skötsel av ETL-processen underlättar användandet och även god tillgång på bra dokumentation påverkar användarvänligheten positivt. Nedan följer en beskrivning av de parametrar som tagits med för att bedöma verktygets användarvänlighet. Inbyggda grafiska utvecklingsverktyg (3.1) Beskrivning: Denna parameter syftar till att bedöma ETL-verktygets inbyggda grafiska utvecklingsverktyg. De grafiska verktygen bör på ett visuellt sätt åskådliggör dataflödet och transformationen av data och ge användaren möjlighet att enkelt utveckla, förändra och påverka ETL-processer. Genom de grafiska verktygen ska användaren komma åt den funktionalitet som ETLverktyget erbjuder och användaren behöver. Vikt: Tre. ”Steg för steg”–verktyg (3.2) Beskrivning: I många typer av datorprogram finns ”steg för steg”-verktyg (engelska: wizard), och sådana förekommer även i ETL-verktyg. Dessa verktyg ska tjäna till att underlätta för användaren att skapa något ofta återkommande genom att höja abstraktionsnivån för utvecklingen. Användaren lotsas genom utvecklingsprocessen steg för steg och kan skapa en laddningsprocess utan att behöva bekymra sig om vissa detaljer. Med hjälp av detta kan utvecklingsarbete komma igång snabbt. Vikt: Två. 26 ETL-verktyg för datavaruhus Mallar (3.3) Beskrivning: Mallar för olika laddningssituationer kan också vara till hjälp för att snabbt komma igång med utvecklingsarbete av ETL-processer. Dessa mallar kan vara vanligt förekommande laddningsscenarion och personen som utvecklar laddningsrutiner kan utifrån dessa mallar skapa sin ETL-process. Vikt: Två. Dokumentation (3.4) Beskrivning: Den hjälp användare kan få av dokumentation om ETL-verktyget bidrar också till hur pass användarvänligt ett ETL-verktyg är. I denna parameter ingår bedömning av inbyggd hjälp, böcker som behandlar ETLverktyget, och åtkomst av hjälp från andra källor, framför allt Internet. Vikt: Tre. Beskrivning av laddningen (3.5) Beskrivning: Liksom kod bör vara väl kommenterad så bör även ETL-processer vara väl kommenterade och lätta att logiskt följa. ETL-verktyget bör alltså erbjuda användaren sätt på vilken den kan följa dataflöden och dataomvandlingen i ETL-processen. Vikt: Två. 3.2.4 Administration och drift (grupp 4) I denna grupp ingår nio parametrar som ska fånga de behov och krav som finns på ETL-verktyget under dess livstid. Eftersom verktyget förhoppningsvis används flera år så är utfallet av gruppen mycket viktigt. Versionshantering (4.1) Beskrivning: Denna parameter har tagits med för att undersöka verktygets stöd för versionshantering av ETL-processer. Versionshantering bör finnas för ETL-processerna för att ge möjlighet att följa utveckling av dem och även ge möjlighet att gå tillbaka till en tidigare version om en ändring blev felaktig. Vikt: Två. Schemaläggning (4.2) Beskrivning: Ett datavaruhus behöver med tiden uppdateras för att innehålla aktuell information. Denna uppdatering sker enklast med automatik för att minska arbetsinsatsen. Därför bör ETL-verktygets arbete gå att schemalägga så att uppdateringen sker automatiskt, gärna på en tid då systemåtkomsten är låg. Anledningen till att köra laddningen när systemen används lite är för att inte försämra prestandan på exempelvis viktiga transaktionssystem. Vikt: Tre. Felsökning (4.3) Beskrivning: Möjligheten att felsöka (engelska: debugging) dataflödet i laddningen ökar möjligheten att hitta eventuella fel. Detta förenklar underhållet av ETL-processer, men även utveckling av nya processer. Vikt: Två Felhantering och loggning (4.4) Beskrivning: När fel uppkommer i ETL-processen är det viktigt att det finns möjlighet till hantering av dessa. Felhantering innefattar upptäckt av fel och val av åtgärder. Fel bör också komma tillkännedom för ansvarig och verktyget bör även ha bra stöd för denna kommunikation. Det kan handla om att skicka 27 ETL-verktyg för datavaruhus meddelande till administratören eller att logga de fel som inträffar. Utifrån denna kommunikation ska det vara möjligt att spåra orsaken till felets uppkomst och exakt vilken data som förorsakade felet. Vikt: Tre. Hårdvarukrav (4.5) Beskrivning: De krav ETL-verktyget har på hårdvaran ingår i denna parameter. Finns den hårdvara som behövs för att köra ETL-verktyget eller måste ny hårdvara införskaffas? Klarar hårdvaran av laddningen inom de tidsramar som finns? I nuläget ska laddningen ske en gång i månaden och utföras över en natt. Vikt: Tre. Programmering (4.6) Beskrvning: Även fast ETL-verktyget helst ska klara sig utan externa program är det viktigt att undersöka om och vilka programmeringsspråk som verktyget stödjer för utveckling av programtillägg. ETL-verktyg som inte stödjer något programmeringsspråk är låsta vi de inbyggda funktioner som finns i verktyget, medan ett verktyg som stödjer någon form av extern programmering däremot ger flexibilitet och möjlighet till utveckling av egna procedurer. De språk som i första hand eftersöks är Visual Basic och C++ eftersom kompetens inom dessa språk finns på PTTFO. Vikt: Två Prestanda (4.7) Beskrivning: De prestandahöjande aktiviteter som finns i ETL-verktyget är av intresse för att minska laddningstiderna. Detta är särskilt viktigt när laddningsfönstret, den tid då laddningen är möjlig, är litet och laddningen sker ofta. Parallellisering av laddningsprocesserna (ETL-processerna) är en typ av prestanda höjande aktivitet. Det är idag svårt att säga hur stort laddningsfönstret kommer att vara, men det är viktigt att undersöka att det i verktyget finns möjlighet att påverkar laddningsprestanda. Vikt: Två Transaktionshantering (4.8) Beskrivning: När data laddas till en databas med transaktionshantering är det viktigt att undersöka hur ETL-verktyget sköter detta. Det kan t ex vara idé att dela upp datan i delar om datamängden är stor, för att minska mängden data som återställs (engelska: rollback) om något fel inträffar. Vikt: Två. Support (4.9) Beskrivning: För framtida problem som kan tänkas uppkomma med ETLverktyget är det viktigt att tillverkaren har god support för sitt verktyg. Även extern support från andra än tillverkaren är viktig. Denna parameter mäter åtkomsten av support. Vikt: Tre. 3.2.5 Kostnader (grupp 5) Kostnaderna för verktyget är förstås av intresse för den som ska betala för det. Två typer av kostnader ingår i denna jämförelse. Denna parametergrupp skiljer sig från de övriga genom att den saknar viktning och betygssättning. Om 28 ETL-verktyg för datavaruhus verktyget är prisvärt kan avgöras genom att titta på priset och jämföra det med verktygets betyg i tidigare parametergrupper. Licenskostnader (5.1) Beskrivning: Med denna parameter avses den fasta licenskostnad som uppkommer vid användning av ETL-verktyget. Kostnaden är beräknad månadsvis. Driftskostnader (5.2) Beskrivning: Dessa kostnader är de som uppkommer för administreringen av verktyget. Det handlar om kostnader uppkommer för att kontrollera loggar och se till att laddningar har lyckats etc. Denna kostnad är också beräknad månadsvis. Med hjälp av dessa parametrar bedömdes ETL-verktygen PowerMart och DTS. I nästa kapitel beskrivs hur PowerMart uppfyller de behov som parametrarna beskriver och i efterföljande kapitel beskrivs DTS. 3.3 PowerMart PowerMart 4.6.1 är en produkt som enligt den amerikanska tillverkaren Informatica ska innefatta alla delar i ett datavaruhus, från laddning till analys. Informatica är ett företag som inriktar sig på analysprodukter för beslutsstöd. 1993 grundades Informatica grundades och företaget har idag knappt 900 anställda [Informatica 2001]. ABB Group Services Center AB, Business Systems (BUS) äger en licens på PowerMart 4.6.1 som kan delas på fem användare. Skulle valet av ETL-verktyg efter jämförelsen falla på PowerMart så skulle BUS administrera och vidareutveckla ETL-processer för detta projekt. Informationen om PowerMart är hämtad från medföljande dokumentation till produkten [Informatica Guide 2001]. 3.3.1 Överblick Innan jag går in på hur PowerMart uppfyller de behov som finns så ges här en kort överblick av hur PowerMart är uppbyggt. PowerMart består av tre enheter, Informatica Server, Informatica Repository och Informatica Client. • • • Informatica Server extraherar, transformerar och laddar data. Denna enhet är motorn i PowerMart som utför själva arbetet i ETL-processen. Informatica Repository är en relationsdatabas som innehåller information, sk metadata, om datakällors och datavaruhus struktur som behövs av ETLprocessen. Repository innehåller även användarnamn och lösenord för åtkomst av data. Informatica Client är applikationen som utvecklaren använder för att definiera och utveckla ETL-processerna. Informatica Client består av tre delprogram, Repository Manager, Designer och Server Manager och de beskrivs nedan. 29 ETL-verktyg för datavaruhus Med programmet Repository Manager kan användare sköta metadata, informationen om datakällors och datavaruhus datastruktur. Härifrån kan en databasen skapas för att lagra denna information. När detta är gjort kan en lagringsplats innehållande information för en datakälla eller datavaruhus skapas i databasen. Med Repository Manager kan man skapa, kopiera och radera lagringsplatser. Det finns även möjlighet att påverka prestanda på databasen för Repository i detta program. Designer är det program som används för att utveckla ETL-processer, som i PowerMart definieras som mappings. I detta program kan användaren definiera källor och mål för datan och skapa transformeringen av datan däremellan. För att skapa transformeringar av data används Transformation Developer som har ett flertal verktyg för specifik funktionalitet. Exempel på funktionalitet i dessa verktyg är sammanslagning av data, filtering av data, och sammanslagning av tabeller. I verktygen specificeras hur omvandlingen av data ska ske och i vissa av verktygen har man tillgång till ett transformationsspråk (engelska: Transformation language) för att definiera omvandlingslogik. Språket innehåller över 60 SQL-likanade funktioner, operatorer, konstanter och variabler. I Designer kan man visuellt se hur arbets- och dataflödet löper. Källor, mål och transformationer representeras av ikoner och flödet representeras med pilar mellan dessa ikoner. I Server Manager skapas sk sessioner för ETL-processerna (mapping). Sessionen styr när ETL-processen ska köras. Här finns även möjlighet att skapa loggfiler och felsöka sessioner. Programmet ger även möjlighet att stoppa en pågående ETL-process. 3.3.2 Parametrar Nedan följer en beskrivning av hur jag uppfattat och bedömt PowerMarts sätt att bemöta de parametrar som ingick i den teoretiska jämförelsen. En summering av resultat återfinns i kapitlet Sammanfattning av jämförelsen. 3.3.2.1 Anslutningsmöjligheter För att läsa data i PowerMart måste dataformatet för datakällan först definieras med hjälp av metadata i Repository. Därefter kan ETL-processer skapas som läser och transformerar datan. PowerMart använder sig av ODBC som i sin tur använder datakällans egna anslutningsrutiner för att ansluta sig till datakällan och de källor som PowerMart kan läsa och skriva till är: • • • Relationsdatabaser: Oracle, Sybase, Informix, IMB DB2, MS SQL Server och Teradata. Filer: textfiler, COBOL(endast källa), och XML Övrigt: MS Excel (endast källa) och MS Access. Från denna lista ser vi att PowerMart har fullt stöd för de aktuella och framtida behoven som finns i denna parametergrupp och får därför betyg tre för dessa parametrar. Dock har jag inte hittat något som tyder på att egna gränssnitt kan utvecklas. 30 ETL-verktyg för datavaruhus 3.3.2.2 Laddningsfunktionalitet Sammanslagning av data (2.1) I PowerMarts Designer finns ett speciellt verktyg för att göra sammanslagningar av data och det kallas för Aggregator Transformation. Detta verktyg innehåller flera funktioner och villkorslogik kan även byggas upp. I verktyget kan användaren skriva kod för sammanslagningen i transformationsspråket, och några exempel på användbara funktioner är medelvärde (AVG), räknare (COUNT), sista värde (LAST) och högsta värde (MAX). Hanteringen av dessa aggregat är tydlig och enkel vilket ger den betyg tre. Surrogatnycklar (2.2) Stöd för att skapa surrogatnycklar finns även i PowerMart Designer. En speciell sekvensgenerator kan användas för att skapa surrogatnycklar för dimensionstabeller i datavaruhuset. Denna generator genererar heltal från ett utgångsvärde som kan anges och genererar sedan heltal med ett angivet intervall. Generatorn lagrar senast använda heltal i Repository och kan därifrån läsa vilket nästa heltal är som ska genereras vid nästa laddning. Stödet för generering av surrogatnycklar bedöms som bra i PowerMart och ges därför betyg tre. Kontroll mot datakällor (2.3) Ett verktyg för att kontrollera värden mot datakällor finns även i Designern. Detta verktyg kallas för Lookup Transformation och kan användas för hämtning av relaterade värden och kontroll av existerande data. PowerMarts hantering av kontroll mot data källor uppskattas som god och ges betyg tre. Stränghantering (2.4) Stränghanteringen i PowerMart sköts av verktyget Expression Transformation som finns tillgänglig i Designern. De transformationsmöjligheter som finns i detta verktyg är de som finns tillgängliga i transformationsspråket, exempelvis sammanlänkning av textsträngar, konvertering till heltal och växling mellan versaler och gemener. Stränghanteringen uppfyller de behov som troligen finns idag och får betyg tre. Tilldelning av grundvärden (2.5) Även tilldelning av grundvärden görs i PowerMart med Expression Transformation. Detta verktyg är ett mångsidigt verktyg för att manipulera data på radnivå och tilldelning av grundvärden kan göras med transformationsspråket. Betyget blir tre. Verifiering och dirigering av indata (2.6) Verifiering och urgallring kan göras på olika sätt i PowerMart. För att kontrollera indata mot en annan datakälla kan Lookup Transformation användas. För att gallra ur felaktig data kan ett annat verktyg, Filter Transformation, användas. I detta verktyg definieras kriterier för vilka värden som ska godkännas och släppas igenom. Värden som inte uppfyller kriteriet släpps inte igenom och laddas därför ej in i datavaruhuset. Enkla kriterierna skapas i 31 ETL-verktyg för datavaruhus verktyg genom att skriva villkorssatser för varje attribut och mer avancerade kriterier kan skapas med hjälp av transformationsspråket. Som ett alternativ till filtreringen kan verktyget Router Transformation användas. Detta verktyg fungerar som Filter Transformation, men data kan istället för att slängas dirigeras om i dataflödet. Detta ger möjlighet att hantera datan som ej uppfyller vissa kriterier. PowerMart bedöms ha goda möjligheterna till verifiering och dirigering av data p g a dessa verktyg och ges betyg tre. Konvertering av datatyper (2.7) De explicita datatypskonverteringar som kan göras i PowerMart är de som ingår i transformationsspråket. För att konvertera datatyper används lämpligast verktyget Expression Transformation och de konverteringar som är möjliga är bl a textsträng till datum (TO_DATE), datavärde till heltal (TO_INTEGER) och datavärde till flyttal (TO_FLOAT). Konvertering av datatyper i PowerMart ges betyg tre, eftersom stöd finns för de vanligaste datatyperna. Pre- och postanrop (2.8) Att göra externa anrop under ETL-processen är möjligt i PowerMart. För varje session kan externa anrop göras före och efter sessionen. Under sessionen kan externa anrop göras i mappning med hjälp av verktyget Stored Procedure Transformation eller External Procedure Transformation. Verktyget Stored Procedure Transformation anropar som namnet antyder en SQL-procedur (engelska: stored procedure) i en databas och verktyg External Procedure Transformation anropar ett programtillägg. PowerMart stödjer COM-objekt (Component Object Model) och Informaticas egna gränssnitt Informatica External Procedures för anrop av programtillägg. Anrop mellan varje datarad går ej att göra och betyg PowerMart erhåller för denna funktionalitet blir därför två. Skötsel av långsamt föränderliga dimensioner (2.9) Genom att bygga upp en kombination av verktygen Filter-, Lookup-, Expression-, och Update Transformation kan långsamt föränderliga dimensioner hanteras på ett bra sätt. Alla tre typer av dessa dimensioner kan hanteras och ett ”steg för steg”-verktyg finns även för att snabbt komma igång. PowerMart tilldelas betyg tre för denna funktionalitet. 3.3.2.3 Användarvänlighet Inbyggda grafiska utvecklingsverktyg (3.1) Designern som ingår i Informatica Client är PowerMarts svar på ett grafiskt utvecklingsverktyg. I Designern har användare tillgång till flera verktyg som utför specifika uppgifter. Flera av dessa har nämnts under parametergruppen laddningsfunktionalitet. Verktygen representeras som ikoner på en arbetsyta och arbets- och dataflöde representeras med hjälp av pilar mellan verktygsikonerna. PowerMarts grafiska utvecklingsverktyg är mycket tydligt och får betyg tre. ”Steg för steg”-verktyg (3.2) I PowerMart har användaren tillgång till två typer av ”steg för steg”-verktyg. Båda verktygen är avsedda för att generera ETL-processer för underhåll av tabeller i en stjärnmodell, var av det första är ett ”komma igång”-verktyg och det andra är ett verktyg för att skapa laddningar av långsamt föränderliga dimensioner. ”Komma igång”-verktyget är avsett för statiska eller sakta växande dimensions- och faktatabeller. Verktyget för att skapa långsamt 32 ETL-verktyg för datavaruhus föränderliga dimensioner stödjer alla tre typer av dessa dimensioner. Verktygen ger PowerMart betyg tre för denna parameter. Mallar (3.3) Mallar är något som saknas i PowerMart och gör att betyget blir noll. Dokumentation (3.4) Den inbyggda hjälpen i PowerMart är i form av kompilerade HTML-sidor. Hjälpen är tydlig och användaren kan klicka sig fram och söka efter det han/hon letar efter. Hjälp finns även att tillgå på Informaticas hemsida, men det kräver registrering. Information om PowerMart från andra håll är däremot begränsad. Jag har inte hittat någon dokumentation på Internet eller i tryckt form. Detta drar ner betyget till en tvåa. Beskrivning av laddningen (3.5) Den hjälp man har till att logiskt följa laddningen är den visuella bild Designern ger av flödet, men möjlighet till kommentarer saknas. Denna är dock bra eftersom den både visar arbetsflödet och dataflödet. Betyget blir två. 3.3.2.4 Administration och drift Versionshantering (4.1) I Designern lagras ETL-processerna i kataloger. I katalogerna finns förutom transformeringarna även källdefinitioner och datavaruhusdefinitioner. För varje ny version man skapar av sin laddning så skapas en ny katalog. I Designern kan olika versioner av samma laddning förekomma, men bara en version är aktiv. Den version som är aktiv är den som exekveras när laddningen körs av schemaläggaren (se nedan). Versions hanteringen i PowerMart uppfattas som tydlig och ges betyg tre. Schemaläggning (4.2) När ETL-processerna ska köras går att schemalägga i PowerMarts Server Manager. För varje ETL-process (mapping) går det att skapa en sk session. Varje session kan schemaläggas genom att bestämma mellan vilka tidsintervall sessionen ska köras. Det går även att ställa in sessionen så att den startar ETLprocessen om en viss fil finns på ett visst ställe. PowerMart tar sedan bort denna ”initieringsfil”. PowerMart uppfyller det som förväntas av verktyget och betyget blir tre. Felsökning (4.3) ETL-processer kan i PowerMart köras i ett sk felsökningsläge. När man kör en ETL-process i detta läge kan man studera måldata, tranformationsutdata och loggfiler. Exekveringen kan styras med hjälp av stoppunkter (engelska: breakpoints) där exekveringen stoppas och läget kan utvärderas. Indata kan också ändras för att se hur utdata blir efter transformationen. Stegfunktion som gör det möjligt att stega sig igenom laddingen saknas dock. Betyget för felsökning av dataladdningar blir två. Felhantering och loggning (4.4) För varje session skapas en loggfil vars detaljrikedom kan ställas av användaren. Nivån på loggningen kan ställas för varje ingående transformation eller för hela sessionen. Om en nivå sätts för hela sessionen så gäller den för 33 ETL-verktyg för datavaruhus alla ingående transformationer oavsett vad de har för inställningar. Den information som lagras i loggfilen är väl strukturerat och i slutet av loggfilen redovisas en summering av laddningen, som bl a innehåller hur många tupler som lyckades och misslyckades vid laddningen. Det finns även möjlighet att arkivera gamla loggfiler. Under en session skapas även en fil för varje mål (tabeller i datavaruhuset) dit data laddas. Denna fil innehåller de tupler som nekades laddning till måldatabasen och filen kan efter laddning öppnas och ge information om vilken data som ej nådde målet. I filen specificeras anledningen till felet och för varje tupel går det att utläsa vilken operation som misslyckades (INSERT, UPDATE, DELETE) och vilka kolumner det berodde på. När en session har körts klart finns möjlighet att underrätta någon, exempelvis en administratör, om detta via e-post. Det finns två olika typer av meddelande som kan skickas, ett för lyckad session och ett för misslyckad session. Hanteringen och loggningen av fel i PowerMart är bra och ger verktyget betyg tre. Hårdvarukrav (4.5) Hårdvarukraven för PowerMart är följande: • • • Informatica Client: 170 MB, 128 MB RAM Informatica Repository: 70 MB, 128 MB RAM Informatica Server: 100 MB, 256 MB RAM Client körs på Windows (95/98/NT4/2000) och Repository och Server körs på Windows(NT4/2000) eller Unix. PowerMart är idag installerat på en Compaq 7000 med två processorer av modell Pentium 200 MHz och 1 GB internminne. Operativsystemet som används är Windows NT 4.0 Server. BUS äger, som tidigare sagt, en licens på PowerMart som får delas upp på fem användare. Fyra av dessa är upptagna och den sista kan alltså bli aktuell för PTTFO. Ett problem med den nuvarande hårdvaran är att de laddningar som redan körs på PowerMart tar hela nätterna och det finns ingen plats för fler laddningar nattetid. Dock kommer BUS att uppgradera både version av PowerMart och datorn under hösten 2001. PowerMart kommer att uppgraderas till version 5.1 och datorn kommer att bli en fyraprocessormaskin med Windows 2000 som operativsystem. Osäkerheten för laddningsutrymme nattetid gör att betyget blir två. Programmering (4.6) I PowerMart ges det utrymme för externa programtillägg som kan utföra omvandlingar av data. Dessa programtillägg anropas för enklare omvandlingar med hjälp av verktyget External Procedure Transformation och för mer avancerade omvandlingar med verktyget Advanced External Procedure Transformation. För att skapa programtillägg för anrop av External Procedure Transformation kan COMobjekt användas. Dessa kan skapas med hjälp av C, C++, Visual C++, Visual Basic, Visual Java och Perl. Behöver man använda sig av de mer avancerade Advanced External Procedure Transformation måste man ska ett programtillägg 34 ETL-verktyg för datavaruhus enligt Informaticas egena gränssnitt. Dessa programtillägg måste skrivas i C++. Möjligheterna till extern programmering uppskattas till goda och ges betyg tre. Prestanda (4.7) I PowerMart finns en mängd olika aktiviteter som kan användas för att höja prestanda på dataladdningar. I Server Manager kan sessioner behandlas buntvis. Sessionerna paketeras in i buntar (engelska: batch) och dessa buntar kan sedan schemaläggas. För varje bunt kan man välja att exekvera ingående sessioner seriellt eller parallellt. Sessioner med små datamängder vars källor och mål är oberoende av varandra kan med fördel köras parallellt för att minska laddningstiden. Detta ställer dock krav på fler processorer. Prestandan kan även höjas på andra sätt, t ex genom att sänka felkänsligheten i transformationen, ändra storlek på buffertar och cache, och justering av Commit-intervall (se parameter 4.8). Inställningarna för dessa måste enligt Informatica testas från fall till fall. De prestanda höjande åtgärder som finns i PowerMart betygssätts till tre. Transaktionshantering (4.8) När data har transformerats hamnar det i en skrivbuffert och kan ifrån denna buffert laddas till målet (datavaruhuset). Det finns två olika sätt för hur laddningen av data kan ske, med målbaserad commit (engelska: target-based commit) eller med källbaserad commit (engelska: source-based commit). Skillnaden mellan dessa är att målbaserad commit styrs efter storleken på skrivbufferten och det angivna commitintervallet, medan källbaserad commit styrs endast av commitintervallet. Commitintervallet anger hur många tupler som ska ha behandlats innan de laddas in. Transaktionshanteringen uppskattas som god och ges betyg tre. Support (4.8) Eftersom BUS äger PowerMart licensen skulle de vid ett val av PowerMart även sköta support av verktyget. BUS säger att de har nio personer som jobbar med PowerMart och att de har resurser för underhåll av en lösning med PowerMart. Risken med detta är att en lösning med blir beroende av BUS. Minskar BUS sina resurser på PowerMart så försämrar det PTTFOs situation, vilket kan leda till att support uteblir. Detta medför att supporten får betyg två. 3.3.2.5 Kostnader Den sista parametergruppen redovisas nedan. Som tidigare nämnts så kan licensen på PowerMart delas på fem användare och skulle valet av ETLverktyg falla på PowerMart blir PTTFO den femte användaren av produkten. Kostnaderna nedan baseras på att licensen delas av fem användare. Skulle användarantalet minska finns det risk att de övriga användarnas kostnader ökar. Det bud PTTFO har fått för en lösning med PowerMart är följande: • Licens kostnad: 14 000 kr/månad • Driftkostnad: 12 000 kr/månad Detta skulle innebära en totalkostnad på 26 000 kr i månaden. 35 ETL-verktyg för datavaruhus 3.4 DTS DTS (Data Transformation Services) är ett ETL-verktyg som ingår i Microsoft SQL Server 2000 (MS SQL 2000) tillverkat av Microsoft. Microsoft som grundades 1975 är förmodligen det största och mest välkända mjukvarutillverkaren i världen och har nära 50 000 anställda i över 60 länder [Microsoft 2001]. I MS SQL 2000 ingår en hel mängd av produkter som härrör lagring och presentation av data, såsom databashanterare, verktyg för integrering mot Internet och analytiska OLAP-funktioner. Informationen om DTS är hämtad från den inbyggda hjälp i MS SQL Server 2000 [SQL OnLine 2000]. 3.4.1 Överblick För att som användare sköta MS SQL 2000 Server används flera olika klientapplikationer. Några av klient applikationerna är, SQL Server Enterprice Manager som är ett administrativt program för att bl a sköta och skapa. relationsdatabaser, Analysis Manager som används för att sköta OLAP och Query Analyser som används för att exekvera SQL-kommandon mot relationsdatabaser. I DTS definieras ETL-processer med ett eller flera sk paket (engelska: DTS Package). Ett paket består av anslutningar mot datakällor och datavaruhus, och olika datatransformationer och uppgifter som utförs under ETL-processen. I paketet definieras även arbetsordningen för de olika uppgifterna som utförs. Det finns två grundläggande sätt att utveckla dessa paket. • Programmera DTS-paket. DTS är uppbyggt på en objektmodell som består av COM-objekt. Dessa objekt kan används i egna program om man använder sig av ett programmeringsspråk som stödjer COM-objekt (ex MS Visual Basic, C++). • Utveckla paket i DTS Designer som ingår i Server Enterprice Manager. Det andra alternativet är att använda MS SQL 2000 grafiska utvecklingsverktyg, DTS Designer, för att skapa DTS-paket. I denna utvärdering av DTS är det senare alternativet av intresse då ett mål är att minimera programmeringsinsatsen och därför kommer jag endast att undersöka de utvecklingsmöjligheter som finns i detta verktyg. I DTS Designer har man tillgång till en mängd olika deluppgifter (DTS Task) som innehåller viss funktionalitet. För att importera, exportera och transformera data finns två deluppgifter att tillgå i DTS Designer, Data Transformation Task och Data Driven Query. För att definiera omvandlingslogik i dessa används ActiveX Script. Två skriptspråk medföljer installationen av MS SQL Server 2000 och det är Microsoft Visual Basic Scripting (VBScript) och Microsoft Jscript. 3.4.2 Parametrar Nedan följer en beskrivning av hur jag uppfattat och bedömt DTSs sätt att bemöta de parametrar som ingick i den teoretiska jämförelsen. En summering av resultatet återfinns i kapitlet Sammanfattning av jämförelsen 36 ETL-verktyg för datavaruhus 3.4.2.1 Anslutningsmöjligheter Anslutningsmöjligheterna i DTS styrs av det underliggande gränssnittet OLE DB som DTS använder sig av för att kommunicera med andra enheter. OLE DB ingår i ett middleware, Universal Data Access (UDA), som har utvecklats av Microsoft och Merant med flera [OLEDB 2001]. Tanken bakom UDA är att utveckla ett standardiserat gränssnitt mot all typ av data, såsom data från relationsdatabaser, data från andra strukturerade format och även icke strukturerade dataformat. Det finns även möjlighet att själv utveckla OLE DB anslutningar mot egna dataformat, men det kräver extern programmering. De anslutningsmöjligheter som finns att tillgå i DTS är: • MS SQL Server 2000, Oracle, DBase, Paradox • MS Access och MS Excel • Övrigt: Textfiler, HTML, och andra OLE DB källor De anslutningsmöjligheter som eftersöks i denna jämförelse finns alltså i DTS och även möjlighet att utveckla egna gränssnitt för OLE DB finns. Därför får DTS betyg tre för aktuella och troliga framtida anslutningarna. Betyget blir ett för utveckling av nya gränssnitt då det kräver programmering. 3.4.2.2 Laddningsfunktionalitet Sammanslagning av data (2.1) I DTS Designer finns inget speciellt verktyg för att skapa sammanslagningar av data. Det man får göra för att slå samman data är att använda SQL. Det går att i verktygen Data Transformation Task och Data Driven Query använda SQL för att plocka ut det data man vill använda sig av och med hjälp av exempelvis AVG, SUM och GROUP BY summera datan. P g a detta får DTS betyg två för denna parameter. Surrogatnycklar (2.2) DTS saknar inbyggt stöd för generering av surrogatnycklar, men detta går att lösa med hjälp av skriptprogrammering (ActiveX Script). Det Microsoft själva använder sig av i sina exempel är att låta datavaruhusets tabeller sköta genereringen av surrogatnycklar. Attributet i tabellen för surrogatnyckeln är i dessa exempel av typen identity field som automatiskt genererar efterföljande heltal. Väljer man denna lösning slipper man programmering, men nackdelen är att ingen återanvändning av nycklar är möjlig. Det begränsade stödet för surrogatnycklar gör att DTS får betyg två. Kontroll mot datakällor (2.3) Kontroll mot datakällor kan i DTS Designer göras i deluppgifterna Data Transformation Task och Data Driven Query. Kontrollrutinen definieras i SQL, vilket gör att kontroll endast kan göras mot relationsdatabaser som stödjer SQL. För att använda kontrollrutinen görs ActiveX anrop till SQLkommandot. Detta kräver alltså en del skriptprogrammering i DTS vilket gör att betygen blir två. 37 ETL-verktyg för datavaruhus Stränghantering (2.4) I deluppgifterna Data Transformation Task och Data Driven Query finns tillgång till stränghantering för att manipulera textdata. Dessa är: • Datetime string. Konverterar källans datumtyp till destinationens format. • Upper/Lower Case. Konvertering mellan stora och små bokstäver. • Middle of string. Plockar ut en del av en sträng, positionsstyrd. • Trim string. Tar bort mellanslag ur strängen. Utöver dessa finns även möjlighet att skriva skript (ActiveX Script) som kan utföra stränghantering, såsom funktioner som plockar ut vänseter eller höger del av textsträngen. Detta ger goda möjligheter till stränghantering vilket gör att DTS ges betyg tre. Tilldelning av grundvärden (2.5) Radvis tilldelning av grundvärden måste i DTS göras med skriptprogrammering i Data Transformation Task eller Data Driven Query. Inget speciellt verktyg finns för detta vilket minskar tydligheten och betyget blir två. Verifiering och dirigering data (2.6) I DTS verifieras indata med hjälp av kontroller mot datakällor (som tidigare beskrivits för parameter 2.3) och skriptprogrammering. För att styra och filtrera data är dock möjligheterna begränsade. Filtrering kan göras med skriptprogrammering eller med SQL i Data Transformation Task och Data Driven Query. Dirigering av data kan göras med Data Driven Query, men data kan endast styras till fyra olika tabeller och därifrån får datan sedan behandlas vidare. Detta göra att betyget blir två. Konvertering av datatyper (2.7) Den implicita konverteringen av datatyper går att styra i Data Transformation Task och Data Driven Qurey. Antingen tillåter man all konvertering vilket medför att det finns risk för att data går förlorad eller blir felaktig, eller så kan man kräva att datatyperna måste vara exakt lika för att tillåta dataöverföring. Ett tredje alternativ som finns går att definiera på eget sätt. De val som finns för detta är, att tillåta utvidgning av datatyp (heltal från två till fyra byte), att tillåta förminskning av datatyp (heltal från fyra byte till två byte), och att tillåta överföring från NULL till NOT NULL kolumner. Utöver denna implicita konvertering finns det även möjlighet till att explicit datatypskonvering via skriptprogrammering. Betyg blir tre. Pre- och Postanrop (2.8) I DTS går det på ett enkelt sätt att göra pre- och postanrop med hjälp av skriptprogrammering. I DTS Designer kan man placera in skriptkod (ActiveX Script Task) i arbetsflödet där man vill att de ska utföras. På detta sätt slipper man blanda in externprogrammering i form av programtillägg som måste skrivas och kompileras utanför DTS. 38 ETL-verktyg för datavaruhus För att ha möjlighet till dessa anrop rad för rad under laddningen kan det sk Multi Phase Data Pump verktyget användas. Detta verktyg ger möjlighet att göra anrop under flera faser av laddningen, bl a före laddning börjar, under laddning (rad för rad) och efter avslutad laddning. Möjligheterna till detta är bra i DTS och därför blir betyget tre. Skötsel av långsamt föränderliga dimensioner (2.9) Det inbyggda stödet för skötsel av dessa dimensioner finns i verktyget Data Driven Query. Hanteringen av data styrs med hjälp av kontroller mot måltabellen dit datan ska laddas och val av åtgärd styrs med hjälp av logik uppbyggd av skriptprogrammering. Fyra olika åtgärder i form av SQL-kommandon kan sedan exekveras exempelvis, en för ny data, en för uppdatering av data, en för radering av data och en för övrig databehandling. Betyget blir två efter som viss skriptprogrammering krävs. 3.4.2.3 Användarvänlighet Inbyggda grafiska utvecklingsverktyg (3.1) För att utveckla DTS-paket finns det, som tidigare sagt, ett grafiskt utvecklingsverktyg (DTS Designer) att tillgå i MS SQL 2000. I detta verktyg kan man som utvecklare definiera sin ETL-process genom att lägga till olika deluppgifter (DTS Tasks), som utför har en speciell funktion, till en arbetsyta. Exempel på deluppgifter är datatransformationer (Data Transformation Task, Data Driven Query), skriptprogram (ActiveX Script Task) och skickande av epost (Send Mail Task). Dessa deluppgifter placeras ut på arbetsytan i form av ikoner och arbetsordningen definieras med pilar mellan ikonerna. Det finns olika typer av pilar som definierar arbetsflödet beroende på utfallet av föregående deluppgift, om deluppgiften lyckades eller misslyckades. DTS grafiska utvecklingsverktyg är tydligt och lätt att förstå, men dataflödet kan ej utläsas och DTS får därför betyg två. ”Steg för steg”-verkyg (3.2) I MS SQL Server 2000 finns även ett ”steg för steg”-verktyg för att snabbt skapa DTS-paket. Verktyget heter Import/Export Wizard. Detta verktyg kan användas för att snabbt skapa en enkel ETL-process. Endast en datakällan kan användas och transformeringen av data är mycket enkel. ”Steg för steg”verktyget är bra för enkla rutiner, men för mer avancerade omvandlingar räcker det inte till och får därför betyg två. Mallar (3.3) För DTS Designer finns det mallar (DTS Package Templates) som angriper vanlig ETL-situationer. Utifrån en mall kan man skapa sitt DTS-paket och slipper alltså börja från början när man utvecklar ett paket. Det går även att skapa egna mallar för senare behov. Denna funktion ger DTS betyg två för denna parameter. Dokumentation (3.4) I den inbyggda hjälpen för MS SQL Server 2000 ingår dokumentation för DTS. Denna dokumentation är består av kompilerade HTML-sidor och kan 39 ETL-verktyg för datavaruhus även läsas från Microsofts hemsida [msdn 2001]. Jag har även hittat flera sidor på Internet som behandlar DTS och även böcker som handlar om utveckling av ETL-processer med DTS. Detta gör att DTS får betyg tre för dokumentation. Beskrivning av laddning (3.5) I DTS finns ingen direkt möjlighet att beskriva sin laddning. På DTS Designerns arbetsyta kan man visuellt se arbetsflödet, men ej dataflödet. I skriptprogrammen kan koden kommenteras, men det ger ingen övergripande bild av ETL-processen. Dessa begränsningar gör att DTS får betyget ett. 3.4.2.4 Administration och drift Versionshantering (4.1) Varje gång ett DTS-paket sparas så sparas en ny version av paketet, dvs den gamla raderas inte utan kan återfås om så önskas. Versionsinformationen lagras i MS SQL Server och om flera versioner finns för ett DTS-paket kan man välja att öppna den version man vill använda. Versionshanteringen i DTS får betyg tre. Schemaläggning (4.2) I Enterprise Manager kan man schemalägga när DTS-paket ska exekvera. Detta görs enkelt genom att ställa in tidsintervallen då paketet ska köras och detta kan göras för varje paket. Det finns dock ingen möjlighet att ställa in någon händelsesstyrd körning av paketen, som t ex existens av fil. Detta gör att betyget blir två. Felsökning (4.3) Felsökning saknas i DTS och därför blir betyget noll. Felhantering och loggning (4.4) Microsoft skiljer på olika typer av fel och delar in dem i två kategorier: • Transformationsfel. Dessa fel kan uppstå när DTS försöker transformera data på ett felaktigt sätt. Detta kan bero på att indata ej passar behandlingen. • Insättningsfel. Detta är fel som uppkommer när transformerad data försöks sättas in i datavaruhuset och datan står i konflikt med befintligt data i datavaruhuset. Exempel på detta är brott mot primärnycklar och referensfel. DTS loggar dessa fel på två olika nivåer. För varje paket loggas varje körning och utfallet av varje ingående deluppgift (DTS Task) i paketet. Denna information sparas i en logfil som är en vanlig textfil. Den andra nivån av loggning i DTS är loggning som sker på deluppgiftsnivå. Denna loggningen innehåller information om exekveringen på radnivå och är möjlig i deluppgifter som utför någon typ av datatransformation. Här finns det även möjlighet att 40 ETL-verktyg för datavaruhus dirigera felaktigt data till speciella textfiler. Detta är bra om man vill se och behandla de tupler som ej kunde laddas. DTS funktionalitet för felhantering och loggning ges betyg tre. Hårdvarukrav (4.5) Hårdvarukraven för Microsoft SQL Server 2000 och således DTS är följande: • Pentium 166MHz, 64 MB • Ca 250 MB hårddisk Microsoft SQL Server 2000 körs på Windows NT eller Windows 2000. Faller valet på DTS kommer verktyget att exekvera på samma dator som datavaruhuset, eftersom DTS ingår i MS SQL Server 2000. PTTFO har idag ett avtal med ABB Group Services Center AB, IT Partner (ITP) på en dator med MS SQL Server 2000 installerat där datavaruhuset ska implementeras. ITP ansvarar för skötsel av denna server, såsom säkerhetskopiering och övrig tillsyn. Denna maskin består av en Intel Pentium processor 866 MHz och ett internminne på 512 MB. Hårddiskutrymmet uppgår till ca 70 GB och operativssystemet är Windows 2000. Idag finns endast en annan databas på denna server och det är PTTFOs egna projektplaneringssystem (OSM) och inga laddningar sker mot den nattetid. Därför finns det i nuläget gott om tid för laddning av datavaruhuset och betyget för lösningen blir tre. Programmering (4.6) Som tidtagare sagts kan DTS-paket utvecklas utanför det grafiska verktyget DTS Designer. DTS-paketet utvecklas i dessa fall i något programmeringsspråk som stödjer COM-objekt. Exempel på sådana språk är Visual Basic och Visual C++. Detta gör det möjligt att skapa egna deluppgifter (DTS tasks) vars funktionalitet inte finns representerade i de inbyggda deluppgifterna i DTS Designer. Progammeringsspråken som stödjer denna utveckling ligger i linje med de eftersökta i denna utvärdering och betyget blir tre. Prestanda (4.7) I DTS finns flera möjligheter att påverka prestanda på laddningarna och få ner laddningstiden. Används Microsoft SQL Server för att lagra datavaruhuset så kan en speciell laddningsrutin, Bulk Load, användas. Denna laddningsrutin är avsedd för att ladda textfiler in till datavaruhuset. Ingen omvandling av data kan göras och ingen loggning av fel förekommer i denna laddningsrutin vilket gör den snabb. En annan möjlighet för att minska laddningstiden är att stänga av felkontroller och loggning i Data Transformation Task. Vilka kontroller som kan stängas av kan i viss mån väljas, men loggning av insättningsfel går ej att koppla ifrån. Deluppgifter (DTS Task) i DTS-paketen kan även exekveras parallellt för att minska laddningstiderna Den funktionalitet som finns för att påverka prestanda uppskattas som bra och ger DTS betyg tre. 41 ETL-verktyg för datavaruhus Transaktionshantering (4.8) För laddningen av data till datavaruhus går det i DTS att dela upp datavolymen buntvis i olika delar, sk batcher. Dessa batcher körs som egna transaktioner och skulle något gå fel i någon tupel så påverkar det endast den batchen där tupeln ingår. Hur batchen påverkas beror på felets typ. Om felet är ett transformationsfel läses nästa tupel tills batchen är full, data tar slut, eller antalet fel överskrider angiven nivå. Om däremot felet har hamnat i batchen och förorsakar ett fel vid insättningen, återställs all data från batchen som lyckats sättas in. Transaktionshanteringen i DTS betygsätts med tre. Support (4.9) Om valet av ETL-verktyg faller på DTS kommer PTTFO själva ansvara för att verktyget fungerar. Den support man då får förlita sig på är den externa supporten man kan direkt erhålla från Microsoft. Förutom att direkt kontakta Microsoft för support tillhandahåller Microsoft en stor mängd artiklar för support på deras hemsida [msdn 2001]. Utöver detta finns även andra Internetsidor som erbjuder support på DTS, bl a http://www.developersdex.com och http://www.sqlmag.com/. Dessa alternativ för support av DTS ger verktyget betyg tre. 3.4.2.5 Kostnader Licenskostnader Eftersom PTTFO idag redan har ett avtal med ABB ITP för drift av en SQL Server där DTS ingår så tillkommer inga kostnader om DTS skulle väljas som ETL-verktyg. De fasta kostnaderna blir därför 0 kr per månad. Driftskostnader De arbetsuppgifter som uppkommer p g a DTS skall vid ett val av DTS utföras av PTTFO själv. Denna kostnad uppskattas till ca 1 000 kr per månad för en timmes arbetsinsats. 42 ETL-verktyg för datavaruhus 3.5 Sammanfattning av jämförelsen Nu har samtliga parametrar gåtts igenom för respektive verktyg och resultatet kan sammanfattas med tabellen nedan. Parametergruppernas betyg är beräknat enligt formeln beskriven på sidan 18. Parameter MS DTS PowerMart Vikt 1 1.1 1.2 1.3 Anslutningsmöjligheter aktuella enheter framtida enheter utveckling 0,89 3 3 1 0,83 3 3 0 3 2 1 2 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 Laddningsfunktionalitet aggregat surrogatnycklar look-up stränghantering tilldelning av grundvärden verfiering och dirigering datatypskonvertering pre- & post anrop långsamma dimensioner 0,75 2 2 2 3 2 2 3 3 2 0,93 3 3 3 3 2 2 3 2 3 2 3 3 2 1 2 2 1 3 3 3.1 3.2 3.3 3.4 3.5 Användarvänlighet grafiska verktyg steg för steg (Wizards) mallar (Templates) dokumentation beskrivning av ETL 0,69 2 2 2 3 1 0,69 3 3 0 2 2 3 2 2 3 2 4 4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.8 4.9 Administration & drift versionshantering schemaläggning felsökning (debugg) felhantering & loggning(mail) hårdvarukrav programmering prestanda transaktionshantering support 0,85 3 2 0 3 3 3 3 3 3 0,90 3 3 2 3 2 3 3 3 2 2 3 2 3 1 2 2 2 3 5 5.1 5.2 Kostnader licenskostnader driftskostnader 0 kr 1 000 kr 14 000 kr 12 000 kr Tabell 3: Sammanfattning av jämförelse av DTS och PowerMart. Anslutningsmöjligheterna i verktygen är likvärdiga. Båda verktygen stödjer de anslutningar som efterfrågas i projektet och i DTS har man även möjlighet att utöka möjligheterna till anslutningar. 43 ETL-verktyg för datavaruhus Laddningsfunktionaliteten är bättre i PowerMart än DTS. PowerMart har fler olika verktyg för specifika uppgifter medan DTS använder sig av färre verktyg som utför flera uppgifter. Detta gör att tydligheten i DTS är sämre än i PowerMart. Det finns dock viss funktionalitet i DTS som är bättre än i PowerMart, t ex pre- och postanrop. Användarvänligheten i verktygen är också likvärdig. PowerMart förlitar sig mer på ”steg för steg”-verktyg och DTS mer på mallar. De grafiska verktyget i PowerMart är ett strå vassare än motsvarande verktyg i DTS, då man i PowerMart förutom arbetsflödet även kan se dataflödet. Det är dock lättare att få fram information om DTS i jämförelse med PowerMart, vilket är mycket viktigt. Verktygens egenskaper för administration och drift är också de likvärdiga. Skillnaderna rent funktionsmässigt är små och man kan säga att PowerMart har något bättre möjligheter till schemaläggning. Kostnadsskillnaden mellan verktygen är dock stor. PowerMart kostar 26 000 kronor per månad, medan DTS uppskattas kosta ungefär 1 000 kronor per månad. 3.6 Slutsats Efter denna summering har jag kommit fram till att DTS är det mest prisvärda och lämpliga verktyget för detta projekt. Laddningsfunktionaliteten har sina brister i DTS, men den innebär inte att funktionalitet saknas. Det som ofta krävs för att skapa de rutiner är kunskap i ActiveX programmering och SQL och denna kunskap finns inom PTTFO. Därför ses inte detta som någon stor begränsning. Den stora tillgången på dokumentation från olika håll om produkten har dessutom gjort att jag ser DTS som ett bättre alternativ än PowerMart. Detta är mycket viktigt för vidareutveckling och stöd av ETL-processer utvecklade i verktyget. 44 ETL-verktyg för datavaruhus 4 Genomförande Detta kapitel beskriver kortfattat uppbyggnaden av datavaruhuset och ETLprocesserna som jag efter valet av ETL-verktyg utvecklade. Bild 9: Systembild av datakälla, datavaruhus och distribution av data. Systemet på bild 8 består av fyra servrar, BaaN (datakällan), MS SQL Server 2000 (datavaruhuset), MS Analysis Server (OLAP) och Crystal Enterprise (distribution av rapporter). Data tankas från BaaN-servern som innehåller all data som denna första version av datavaruhuset använder. Det första steget i dataflödet är att befintliga skript i BaaN extraherar data ur den underliggande Oracledatabasen. I dessa skript sker en viss tvättning och urgallring av data och tillslut hamnar datan i olika extraktfiler (ASCII), en fil per databastabell. Dessa extraktfiler kan ses som behandlingsarean i detta system, men ingen behandling sker just när datan ligger i filerna. Datavaruhuset består av två datalager (bas- och analyslager) och en server för OLAP-kuber. Nedan beskrivs dessa och laddningarna mellan dem. I slutet beskriver jag även hur önskemålen om användargränssnitten för rapporter och analyser löstes. 45 ETL-verktyg för datavaruhus 4.1 Baslagret Baslagret är det lägsta datalagret i datavaruhuset och det är hit datan från extraktfilerna kommer först. Baslagret är uppbyggd som en relationsdatabas och strukturen av denna påminner mycket om BaaNs underliggande Oracledatabas. Relationer mellan tabellerna är de samma, men vissa attribut i tabeller som inte är intressanta för rapporter och analyser har tagits bort. Bild 10: Fysisk uppbyggnad av Baslager Baslagret ska användas av rapportgeneratorer för att skapa rapporter. Utifrån baslagret skapas även stjärnmodeller som lagras i nästa datalager, analyslagret. Tabellerna i baslagret beskrivs i bilaga C. 4.2 Laddning av baslager Laddningen av baslagret sköts av DTS och jag har utvecklat laddningarna i DTS Designer. Jag har försökt minimera programmeringsinsatsen och använt de inbyggda verktygen så mycket som möjligt. Den programmering som förekommit har gjorts med Visual Basic Script och SQL. Alternativet till att använda Visual Basic Script skulle ha varit att använda Jscript, men Jscript visar sig dock ha sämre prestanda än Visual Basic i DTS. I en undersökning utförd av Vieira [Vieira 2000] laddades 15 174 dataposter med 30 kolumner med båda alternativen. Överföringen av data tog med Visual Basic 13 sekunder och med Jscript 19 sekunder. Det verkar som att undersökningen endast omfattar en laddning och resultaten är kanske därför inte så överförbara till verkligheten. Microsoft menar dock också att Visual Basic är snabbare än Jscript. Detta i kombination med den breda kunskap i Visual Basic som finns på PTTFO gjorde att valet föll på detta språk. För varje extraktfil har jag utvecklat ett tillhörande DTS-paket som laddar extraktfilens data till baslagret. Man kan säga att det finns två typer av extraktfiler, filer som innehåller information om behandlingen av dess data och filer som inte gör det. Skillnaden mellan dessa gör att DTS-paket för laddning av den första typen av extraktfiler inte behöver kontrollera om datan finns sen tidigare i baslagret, eftersom fil innehåller informationen om behandlingen. 46 ETL-verktyg för datavaruhus Detta måste dock DTS-paket för den andra typen av extraktfiler göra för att veta hur datan ska behandlas. För att logga fel används DTS inbyggda loggningsfunktion för de deluppgifter som utför laddning. Felaktig data som av någon anledning inte kan sättas in i datavaruhuset lagras av DTS i en fil med filändelsen Source. Rimlighetskontroller förekommer i vissa paket och data som ligger utanför rimlighetsramarna lagras i en särskild fil med filändelse Verify. För att en administratör lätt skall kunna gå igenom den data som ej laddades sammanförs båda dessa filer till ett Excelark. Datan kan sedan behandlas och rättas i Excel och sedan sparas som en nya extraktfil för att laddas på nytt. Algoritm för DTS-paket för laddning av baslagertabell: 1. Initiering av DTS-paket, bl a sätts namn på extrakt- och loggfiler 2. Laddar extraktfil till baslager, rad för rad: 2.1. Verifiering av indata. Om data ligger utanför rimlighetsgränser: 2.1.1. Lagra indata i fil för orimligt data (Verify) och ange orsak till fel. 2.1.2. Fortsätt med nästa datarad. 2.2. Annars: 2.2.1. Om primärnyckeln inte finns i baslagertabell: 2.2.1.1. Utför INSERT 2.2.2. Annars: 2.2.2.1. Utför UPDATE 3. Ladda DTS fil med felaktig data till Excelark för rättning 4. Ladda fil innehållande orimlig data till Excelark för rättning. 5. Filhantering 5.1. Flytta behandlad extraktfil till plats för behandlat data. 5.2. Radera filer innehållande felaktig (Source) och orimlig data (Verify). Om information om databehandlingen finns i extraktfilen styr denna valet av åtgärd i punkt 2.2.1, istället för kontroll av primärnyckeln i måltabellen. Nedan följer ett exempel på ett DTS-paket för laddning av extraktfil till baslagret som bygger på denna algoritmen. 47 ETL-verktyg för datavaruhus Bild 11: Exempel på DTS-paket för laddning av baslagertabell. De tre övre ikonerna (Extraktfil, Lookup, Baslager) på arbetsytan definierar de anslutningar som behövs av DTS-paketet. Den första deluppgiften som utförs är av typ ActiveX Script Task och kallas för Initiering. Denna deluppgift utför preanrop, såsom initiering av datakällor och skapande av loggfiler före laddningen påbörjas. Denna deluppgift motsvarar algoritmens första steg (se bilaga A1 för kodexempel). När initieringen är klar fortsätter exekveringen till deluppgiften Laddning till baslager som är en Data Driven Query (se bilaga A2 för kodexempel). Denna deluppgift motsvarar steg två i algoritmen och utför kontroller och laddning av data. Anslutning Lookup används för att kontrollera om data finns sen tidigare i baslagret och denna används när extraktfilen saknar information om behandlingen. Efter detta laddas filerna för felaktigt data till Excel för vidare behandling, steg tre och fyra i algoritmen. Först laddas DTS egna fil för felaktigt data (Source) och sedan filen innehållande data utanför rimlighetsramarna (Verify). Denna laddning utförs av två Data Transformation Task som representeras med heldragna pilar på arbetsytan. Avslutningsvis exekveras deluppgiften Filhantering som är ett ActiveX Script Task (se bilaga A3 för kod exempel) som utför algoritmens sista steg, steg fem. Detta är en form av postanrop. Totalt har jag skapat nio DTS-paket som sköter laddningen av baslagret. 4.3 Analyslagret Analyslagret är det andra datalagret i datavaruhuset. Här är datan lagrad i faktaoch dimensionstabeller och dessa är strukturerad i stjärnmodeller. Analyslagret utgör grunden för de OLAP-kuber som genereras senare i Analysis Server, men kan även användas av rapportverktyg för generering av rapporter.. 48 ETL-verktyg för datavaruhus Nedan följer stjärnmodellen jag utvecklade för beställd köpvolym (inköpsdata). Bild 12: Stjärnmodell för beställd köpvolym i analyslager Denna stjärnmodell består av en faktatabell och sex dimensionstabeller. Faktatabellen innehåller köpvolymen uppdelad på orderradsnivå, dvs varje datarad i faktatabellen kommer från en beställning av en vara eller tjänst. Dimensionstabellerna i stjärnmodellen är inköpsorder, personalregister, artiklar, leverantörer, enheter och orderpositioner (orderrader). Med dessa kan faktat i faktatabellen senare analyseras i OLAP-verktyg. Tabellerna i analyslagret beskrivs i bilaga D. 4.4 Laddning av analyslagret Denna laddning, liksom laddning av baslagret, sköts av DTS. Laddningen av analyslagret innebär en omstrukturering av data, eftersom datan i baslagrets ligger lagrat enligt en relationsmodell och analyslagret är strukturerat med stjärnmodeller. Vad innebär detta för laddningen av fakta- och dimensionstabellerna? För att utnyttja de fördelar som finns i samband med användande av surrogatnycklar bestämde jag mig för att använda sådana för dimensionstabellerna i analyslagret. Datatypen för surrogatnycklarna är heltal och dessa tilldelas löpande till inkommande data från baslagret. Detta innebär att laddningen av analyslagret måste hantera tilldelning och kontroll av surrogatnycklar. I min första version av analyslagret utvecklade jag dock sk triggers för att sköta tilldelningen av surrogatnycklar (se bilaga B1). Med denna lösning skulle varje dimensionstabell själv sköta tilldelning och återanvändning av surrgatnycklar och på så vis skulle DTS-paketen slippa detta. Denna lösning fungerade bra på tabeller som bestod av upptill 20 000 poster, men efter det tog laddningen lång tid. Anledningen till detta berodde på att triggern för varje ny datapost undersökte om det fanns några nycklar som kunde återanvändas innan den satte in den nya dataposten. Jag övergav denna lösning och 49 ETL-verktyg för datavaruhus implementerade istället en lösning i DTS med Visual Basic, där återanvändning av nycklar automatiskt kopplades bort om det inte fanns några nycklar att återanvända (se bilaga A4). Det tyngsta arbetet i omorganisering av data mellan baslagret och analyslagret är att skapa faktatabellen. Den består av referenser till flera dimensionstabeller och dessa referenser måste för varje faktarad hämtas från dimensionstabellerna. Jag valde att använda SQL (se bilaga B2) för denna operation, mycket p g a att Microsoft själva rekommenderade denna lösning och för att jag själv märkte att den var snabb. Algoritm för laddning av dimensionstabell: 1. Initiera laddningen, aktivera återanvändning av surrogatnycklar. 2. Läs data rad för rad från baslagret: 2.1. Om återanvändning av surrogatnycklar aktiverad: 2.1.1. Om oanvända surrogatnycklar finns i måltabell: 2.1.1.1. Använd högsta oanvända surrogatnyckel. 2.1.2. Annars: 2.1.2.1. Avaktivera återanvändning 2.1.2.2. Välj nästföljande surrogatnyckel 2.2. Annars: 2.2.1.Välj nästföljande surrogatnyckel 2.3. Sätt in data i dimensionstabellen med surrogatnyckel. 3. För datarader i baslagret som är markerade för uppdatering: 3.1. Uppdatera dessa datarader i analyslagret 4. För datarader som finns i analyslagret, men ej i baslagret 4.1. Radera dessa datarader i analyslagret. Bild 13: DTS-paket för laddning av dimensionstabell Bild 13 visar ett DTS-paket som implementerar algoritmen för laddningen av dimensionstabeller. Uppkopplingar mot källor och mål (baslager, lookup, analyslager) ses överest på arbetsytan. Exekeringen börjar med ActiveX Script minCheck=True, vilken ser till att återanvändning av surrogatnycklar från början är aktiverad (punkt 1 i algoritmen). Efter detta följer tre Data Driven Query, var 50 ETL-verktyg för datavaruhus av den första, INSERT utför insättning av nya datarader till analyslagret och den andra, UPDATE, utför uppdatering av befintligt data i analyslagret. Den tredje radera data i analyslagret som inte finns i baslagret och data i bas- och analyslagret blir på detta sätt samstämmigt. Dessa tre deluppgifter motsvarar punkt 2 till 4 i algoritmen. Algoritm för laddning av faktatabell: 1. Plocka ut primärnycklar för de dataposter som finns i analyslagret, men ej i baslagret 1.1. Radera dessa dataposter från faktatabellen 2. Plocka ut referenser och fakta för dataposter som finns i baslagret, men ej i analyslagret 2.1. Sätt in dessa dataposter i faktatabellen. 3. Plocka ut primärnycklar för de dataposter som finns i analyslagret, men ej i baslagret och som dessutom är markerade för uppdatering: 3.1. Uppdatera dessa dataposter i faktatabellen. Bild 14: DTS-paket för laddning av faktatabell i analyslagret. Även i detta DTS-paket ses anslutningarna (baslager och analyslager) överst på arbetsytan. Någon kontroll av data (Lookup) behövs inte eftersom SQL används i deluppgifterna för att välja ut datarader för behandling. Laddningen består av tre Data Driven Query var av den första, DELETE, plockar ut de datarader som finns i analyslagret, men inte i baslagret. Dessa datarader raderas från analyslagret, se punkt 1 i algoritmen. Nästa deluppgift, INSERT, sköter insättning av nya faktarader (datarader) i faktatabellen. Deluppgiften ser till att referenser för fakta till dimensionstabellerna blir rätt (se bilaga B2). När referenserna har kopplats sätts dataraden in i faktatabellen. När alla nya rader har satts in uppdateras data i analyslagret som är markerat för uppdatering i baslagret. Detta medför att data i bas- och analyslager blir samstämmigt. Laddning och uppdatering av analyslagret sköts av sju DTS-paket, ett för varje tabell. 51 ETL-verktyg för datavaruhus 4.5 Konfiguration av DTS Totalt har jag skapat 17 DTS-paket för uppdatering och laddning av datavaruhuset. Laddningen har jag ordnat så att laddningen av bas- och analyslager sker först och därefter uppdateras OLAP-kuber (se kapitel OLAPkuber). Laddningsprocessen körs igång av ett DTS-paket kallat MAIN. Detta DTS-paket körs på SQL Servern en gång i timmen och drar igång laddningen om en startfil, som genereras av extrakskripten i BaaN, har skapats. Denna kontroll är skriven i Visual Basic och om filen finns startar MAIN de andra DTS-pakten som utför laddningen. Laddningen är indelad i fem steg (grupper): 1. Data som är gemensamt för flera avdelningar laddas till baslager (BAS_COM). 2. Data som är tillhör en specifik avdelning laddas till baslager (ex BAS_PUR för inköpsdata). 3. Överföring av data mellan baslager och analyslager för gemensam data (ANL_COM) 4. Överföring av data mellan baslager och analyslager för specifik avdelningsdata (ex ANL_PUR för inköpsdata). 5. Uppdatering av OLAP-kuber. Bild 15: Exekvering av DTS-paket. För att lättare överblicka laddningen av datavaruhuset har jag sammanfört loggfilerna som genereras av deluppgifterna i den grupp av laddning som de ingår. På det sättet får man fem loggfiler att gå igenom efter en laddning, en för varje grupp. 52 ETL-verktyg för datavaruhus Bild 16: DTS-paket som exekverar underliggande paket. DTS-paketet på bild 16 exekverar DTS-paketen för laddningen av gemensam data till baslagret (BAS_COM). I slutet av paketet sammanförs loggfilerna från de olika paketen som exekverats till en gemensam loggfil. 4.6 OLAP-kuber För att möjliggör OLAP-analyser av köpvolymen för leverantörer skapade jag en OLAP-kub som lagras på Analysis Server. Datan som kuben bygger på måste vara strukturerat i en stjärn- eller snöflingemodell, så data läsas därför från analyslagret. I verktyget Microsoft Analysis Manager, som ingår i MS SQL Server 2000, kan man definiera hur OLAP-kuben ska se ut., här väljer man vilka tabeller man vill använda för fakta och dimensioner. Dimensionstabellernas attribut kan ordnas i hierarkier för dimensionerna och även attribut i en faktatabell kan plockas ut till en dimension. Detta är t ex lämpligt för att skapa tidsdimensioner som kan baseras på ett datumattribut i faktatabellen. Den OLAP-kub som jag definierade bygger på en faktatabell och fem dimensionstabeller i analyslagret. Ytterligare en dimension, tidsdimensionen, skapas utifrån faktatabellens datumattribut, vilket gör att sex dimensioner kan användas för att analysera fakta i faktatabellen. När OLAP-kuben genereras skapas automatiskt aggregat, summering av data, efter hur dimensionerna är strukurerade. För varje OLAP-kub finns tre olika lagringssätt. • MOLAP, data lagras i kuben. • ROLAP, data refereras till underliggande datalager (analyslagret). • HOLAP, aggregat lagras i kuben, men övrigt data refereras till underliggande datalager. Jag valde att använda mig av MOLAP eftersom det ger snabbast svarstider mot OLAP-kuben. 53 ETL-verktyg för datavaruhus 4.7 Användargränssnitt för OLAP-kuber Det gränssnitt som användarna använder för att analysera datan i OLAPkuberna är Excel 2000. Anledningen till att jag valde detta program som gränssnitt är att programmet redan fanns på ABB och att användarna är vana vid det. Det finns flera verktyg för att analysera OLAP-kuber på marknaden och säkert sådana som är bättre än Excel, men att analysera detta ingick inte i detta examensarbete. I Excel 2000 använder man sig av Excels pivottabeller för att arbete med analysen. Genom att koppla upp programmet med HTTP mot Analysis Server kan användaren se datan i sitt Excelark. Dimensioner kan flyttas för att studera datan ur olika synvinklar och det går också att göra ”drill-down” i dimensioner med hierarkier. Bild 17: Pivottabell i Excel för analys av OLAP-kub. 4.8 Användargränssnitt för rapporter Önskemålet för rapporterna var att de skulle vara åtkomliga från ABB intranät, så att ingen installation skulle krävas på varje användares arbetsstation. Jag bestämde mig för att använda Seagate Softwares lösning för utveckling och distribution av rapporter, eftersom deras produkter redan fanns på ABB. För att skapa rapporter använde jag Crystal Report (som är en Seagate produkt) och kopplade upp mig mot baslagret i datavaruhuset för att hämta data till rapporterna. Uppkopplingen mot databasen gjordes i Crystal Report med ODBC. För att distribuera rapporterna installerade jag Crystal Enterprise (Seagate produkt) på en webserver på ABB. Denna produkt möjliggör distribution av rapporter skapade med Crystal Report. Användarna kan via sin webbrowser (Internet Explorer) komma åt rapporterna och skriva ut dem eller spara dem på sin dator. 54 ETL-verktyg för datavaruhus 5 Resultat och framtid Vad kan man säga när detta examensarbete nu är utfört? Fick användaren tillgång till rapporter och analyser? Var DTS det riktiga valet av ETL-verktyg, fungerade det vid laddningen av datavaruhuset och vad kan man säga om jämförelsemetoden? Om vi börjar att titta på hur jämförelsen föll ut och viktningen av parametrar. Jag hade när jag började med detta examensarbete ingen erfarenhet av datavaruhus och laddningen av dessa. Nu efter att jag har satt upp ett datavaruhus och skapat laddningsrutiner för detta så har jag lärt mig en hel del saker som är viktiga att tänka på. Vissa av de parametrar som jag hade med i jämförelsen skulle t ex ha fått en annan vikt. Detta gäller bl a parameter 2.8 (pre- och postanrop) som hade fått en högre viktning, eftersom jag använde sådana ofta och bl a parameter 3.2 (”steg för steg”-verktyg) och 3.3 (mallar), eftersom dessa har jag inte använt alls i utvecklingen av ETL. Var nu DTS det rätta valet? Intrycket jag fick av DTS under utvärderingen var att verktyget var lättarbetat, trots att det saknade viss funktionalitet som jag då trodde skulle försvåra utveckling av ETL-processer. Efter att nu ha utvecklat ETL-processer med DTS så tycker jag fortfarande att verktyget är lätt att arbeta med. Det går fort att utveckla en laddningsprocess och dokumentationen om DTS var inte överdriven till det positiva. Visst hade det varit bra med felsökning av DTS-paketen, det hade sparat tid vid utvecklingen och visst hade det varit bra med PowerMarts surrogatnyckelgenerator för att lättare generera surrogatnycklar, men dessa saker gick att lösa i DTS. Och kanske ändå viktigare, de gick att lösa i DTS till en mycket lägre kostnad. En av de bättre sakerna med DTS som jag nu ser det i efterhand är möjligheten till skriptprogrammeringen. Målet var i och för sig att minimera programmeringen vid utvecklingen av ETL-processer, men viss programmering kommer man nog aldrig ifrån, som t ex filhantering. Att DTS hade möjlighet att till denna programmering direkt i verktyget underlättade mycket. Man slipper skriva externa program som anropas av DTS för att utföra sådana uppgifter. DTS fungerar bra för laddningen av datavaruhuset och jag tycker i efterhand att valet var riktigt. Personalen på inköpsavdelning kan idag arbeta med rapporter och analyser i en testmiljö på ABB. Rapporter kan användare med behörighet komma åt via intranätet och analyser kan utföras med ett verktyg de känner igen, Excel. Det som nu står för dörren i detta projekt är att bredda datavaruhuset, dvs plocka in data från fler avdelningar, och även att göra en utredning på lämpliga rapport- och analysverktyg. 55 ETL-verktyg för datavaruhus 6 Tack Först vill jag tacka mina handledare jag haft för detta examensarbete. Tommy Jakobsen ABB Power Technology Products AB Johan Karlsson Umeå Universitet Sedan vill jag tacka följande personerna för att de på ett eller annat sätt har hjälpt mig under detta examensarbete. Curt Karlsson ABB Power Technology Products AB Fredrik Fritzon ABB Group Services Center AB, IT Partner Erling Nääs ABB Power Technology Products AB Torbjörn Sjödin ABB Group Services Center AB, Business Systetems Thomas Söderberg ABB Group Services Center AB, IT Partner Carl-Henrik Wigert ABB Power Technology Products AB 56 ETL-verktyg för datavaruhus 7 Ordlista ABB Asea Brown Boveri Behandlingsarea (engelska: Staging Area). Lagringsplats för data innan den laddas till datavaruhuset. Här kan tvättning, justering och omstrukutering av data ske. Formatet på behandlingsarean kan t ex vara enkla filer eller databaser. BUS ABB Group Services Center AB, Business Systems COM (engelska: Component Object Model). Objektmodell för programmering utvecklad av Microsoft. Data Mart Logisk del av datavaruhuset. Uppdelningen kan vara avdelningar som ingår i ett företag, såsom inköpsavdelning och finans. Datavaruhus Samlingsplats för data avsedd för rapporter, analys och beslutstöd. DTS Data Transformation Services. Ett ETL-verktyg från Microsoft. ERP Enterprise Resource Planning. Affärssystem som är uppbyggt som en klient/server lösning. ETL Extraction, Transformation , Loading. Processer som sköter införandet av data till datavaruhuset. ITP ABB Group Services Center AB, Business Systems OLAP On-Line Analysis Services. Dimensionell analys av data. PowerMart Ett ETL-verktyg från Informatica. PTTFO ABB Power Technology Products AB, Transformers 57 ETL-verktyg för datavaruhus 8 Källförteckning [Kimball 1998] Kimball, Ralph & Reeves, Laura & Ross, Margy & Thornthwaite. (1998) The Data Warehouse Lifecycle Toolkit. Wiley [Elmasri 2000] Elmasri, Ramez & Navathe, Shamkant B. (2000). Fundamentals of Database Systems. (3rd ed) Addison-Wesley [Thomsen 1999] Thomsen, Erik & Spofford, Geroge & Chase, Dick (1999). Microsoft OLAP Solutions. Wiley [Vieira 2000] Vieira, Robert (2000). Professional SQL Server 2000 Programming. Wrox [Cox III 1995] Cox III, James F. & Blackstone, John H. & Spencer, Michael S. (1995). Apics Dictionary. (8th ed) [SQL OnLine 2000] SQL Server Books OnLine, hjälpfiler från Microsoft SQL Server 2000. (2000) [Informatica Guide 2001] Informatica Guide, hjälpfiler från Informatica PowerMart. (2001) [Gupta 1997] Gupta, Vivek R. An Introduction to Data Warehousing. (1997) http://www.sserve.com/dwintro.asp 2001-09-13 [Scott 2000] Scott, Van. Extraction, Transformation, and Load issues and approaches. (2000) http://www.tdan/com/i011hy04.htm 2001-09-13 [Meyer 2001] Meyer, Steven R. Which ETL Tool is Right for You? (2001) http://www.dmreview.com/master.cfm?NavID=193&EdID=3084 2001-1217 [Allison 2001] Allison Bryan. Targeting ETL Success (2001) http://www.dmreview.com/editorial/dmreview/print_action.cfm?EdID=333 4 2001-12-17 [Navarro 2000] Navarro, Robert. Solving the Surrogate Key Problem For Business Intelligence Implementations. (2000) http://datawarehouse.ittoolbox.com/browse.asp?c=DWPeerPublishing&r=% 2Fpub%2FBN101901%2Epdf 2001-12-12 [Pendse 2001] Pendse, Nigel, What is OLAP! (2001) http://www.olapreport.com/fasmi.htm 2001-12-13 [Lupin 2001] Bernard Lupin, Try OLAP! (2001) http://perso.wanadoo.fr/bernard.lupin/english/ 2001-12-13 [olde db 2001] ole db (2001) http://www.oledb.com/ 2001-09-17 58 ETL-verktyg för datavaruhus [Informatica 2001] Informatica http://www.informatica.com 2001-12-13 [msdn 2001] msdn http://msdn.microsoft.com 2001-09-19 [Microsoft 2001] Microsoft http://www.microsoft.com 2001-12-12 59 Bilagor Bilaga A – Visual Basic skript A1 – Exempel på skript för att initiera DTS-paket ' Syfte: ' 1. Initierar paket med globala variabler. ' 2. Skapar logfil för .Source (DTS fil för icke godkänd data) om denna ej redan finns. Function Main() Dim fs, file Err.Clear On Error Resume Next ' 1. Initiering av paket DTSGlobalVariables.Parent.Connections("Extraktfil").DataSource = _ DTSGlobalVariables("extractFile") DTSGlobalVariables.Parent.Tasks("DTSTask_DTSDataDrivenQueryTask_1").CustomTask. ExceptionFileName = DTSGlobalVariables("logFile") DTSGlobalVariables.Parent.Connections(".Source File").DataSource = _ DTSGlobalVariables("logFile") & ".Source" DTSGlobalVariables.Parent.Connections("BAS_COM_MAIN").DataSource = _ DTSGlobalVariables("excelFile") ' 2. Skapar logfil .Source Set fs = CreateObject("Scripting.FileSystemObject") Set file = fs.OpenTextFile(DTSGlobalVariables("logFile") & ".Source", 8,true) file.WriteLine "enhet;X;X;X" file.Close ' Felkontroll if Err.Number = 0 Then Main = DTSTaskExecResult_Success Else Main = DTSTaskExecResult_Failure End if End Function A2 – Exempel på skript för transformering av data i Data Driven Query ' Syfte: Kopiera över data från källa till mål Function Main() DTSDestination("enhet") = DTSSource("Col001") DTSDestination("benämning") = DTSSource("Col002") DTSDestination("fys_kvantitet") = DTSSource("Col003") DTSDestination("avrundningsfaktor") = DTSSource("Col004") ' Kontroll av primärnyckel och val av åtgärd. If IsNull(DTSSource("Col001")) Then Main = DTSTransformStat_Error Else If IsEmpty( DTSLookups("lookup").Execute(DTSSource("Col001")) ) Then Main = DTSTransformStat_InsertQuery Else Main = DTSTransformStat_UpdateQuery End If End if End Function A3 – Exempel på skript för filhantering i DTS-paket ' Syfte: ' 1. Flyttar extraktfil till old-katalog ' 2. Raderar Source-fil. Function Main() Dim fs, file, pos, filename Err.Clear On Error Resume Next Set fs = CreateObject("Scripting.FileSystemObject") ' 1. Flytta extraktfil till old-katalog, efter att först ha tagit bort föregående extraktfil pos = InStrRev(DTSGlobalVariables("extractFile") , "\" , -1, 1) filename = Right(DTSGlobalVariables("extractFile"), _ len (DTSGlobalVariables("extractFile")) - pos) if fs.FileExists(DTSGlobalVariables("oldDir") & filename) Then Set file = fs.GetFile(DTSGlobalVariables("oldDir") & filename) file.delete 'Radera gammal extraktfil End if Set file = fs.GetFile(DTSGlobelVariables("extractFile")) ' Flytt ny extraktfil fs.MoveFile DTSGlobelVariables("extractFile"), DTSGlobelVariables("oldDir") ' 2. Raderar .Source-fil if fs.FileExists(DTSGlobalVariables("extractFile") & ".Source") Then Set file = fs.GetFile(DTSGlobelVariables("extractFile") & ".Source") file.delete ' Raderar .Source-fil End if If Err.number = 0 Then ' Felkontroll Main = DTSTaskExecResult_Success Else Main = DTSTaskExecResult_Failure End If End Function A4 – Exempel på skript tilldelning av surrogatnycklar ' Syfte: Tlldelar värden för målel. Återanvändning av surrogatnycklar vid behov. Function Main() Dim minSurrogate, maxSurrogate DTSDestination("posnummer") = DTSSource("posnummer") DTSDestination("ordernummer") = DTSSource("ordernummer") ' Återanvändning av nycklar if DTSGlobalVariables("mincheck").Value = True Then minSurrogate = DTSLookups("minLookup").Execute – 1 if IsNull(minSurrogate) Then Else DTSGlobalVariables("mincheck").Value = False maxSurrogate = DTSLookups("maxLookup").Execute if IsNull(maxSurrogate) Then DTSDestination("orderpos_nyckel") = 1 Else DTSDestination("orderpos_nyckel") = maxSurrogate +1 End if DTSDestination("orderpos_nyckel") = minSurrogate End if Else Main = DTSTransformstat_InsertQuery ' Slut på återanvändning maxSurrogate = DTSLookups("maxLookup").Execute if IsNull(maxSurrogate) Then ' Tom tabell maxSurrogate = 1 Else ' Ej tom tabell maxSurrogate = maxSurrogate +1 End if DTSDestination("orderpos_nyckel") = maxSurrogate Main = DTSTransformstat_InsertQuery End if End Function Bilaga B – SQL B1 – Trigger för tilldelning av surrogatnycklar CREATE TRIGGER SurrogatTrigger ON ANL_COM_ENHETER INSTEAD OF INSERT AS BEGIN DECLARE @key int -- Denna trigger skäter val av surrogatnyckel för nya datarader. -- Tilldelar @key lägsta lediga surrogatnyckel i måltabellen SELECT @key = MIN(enhet_nyckel) –1 FROM ANL_COM_ENHETER WHERE (enhet_nyckel-1) > 0 AND (enhet_nyckel-1) NOT IN (SELECT enhet_nyckel FROM ANL_COM_ENHETER) -- Sätt in rad i tabell, surrogatnyckel (@key) först INSERT INTO ANL_COM_ENHETER SELECT ISNULL(@key, ISNULL((SELECT MAX(enhet_nyckel) FROM ANL_COM_ENHETER)+1, 1), enhet, benämning, fys_kvantitet, avrundningsfaktor FROM INSERTED END B2 – SQL-sats för skapande av faktarad för insättning i faktatabell SELECT ORD.order_nyckel, LEV.lev_nyckel, ENH.enhet_nyckel, PER.pers_nyckel, ART.art_nyckel, POS.orderpos_nyckel, RAD.behovsdatum, RAD.ak_antal, RAD.inköpspris, RAD.valuta, RAD.ak_volym_ov, RAD.ak_volym_lv FROM (SELECT * FROM BAS_PUR_ORDERRADSDATA AS BAS WHERE NOT EXISTS ( SELECT * FROM ANL_PUR_BESTVOL AS VOL INNER JOIN ANL_PUR_ORDERPOS AS POS ON VOL.orderpos_nyckel=pos.orderpos_nyckel WHERE POS.ordernummer=BAS.ordernummer AND POS.posnummer=BAS.posnummer)) AS RAD INNER JOIN ANL_PUR_INKÖPSORDER AS ORD ON RAD.ordernummer=ORD.ordernummer INNER JOIN ANL_COM_LEVERANTÖRER AS LEV ON ORD.leverantör=LEV.leverantör INNER JOIN ANL_COM_PERSONALREGISTER AS PER ON LEV.kontaktperson=PER.anställningsnummer INNER JOIN ANL_COM_ENHETER AS ENH ON RAD.inköpsenhet=ENH.enhet INNER JOIN ANL_PUR_ARTIKLAR AS ART ON (RAD.artikelnummer=ART.artikelnummer AND RAD.artikeltyp=ART.typ) INNER JOIN ANL_PUR_ORDERPOS AS POS ON (RAD.ordernummer=POS.ordernummer AND RAD.posnummer=POS.posnummer)