Judendom
advertisement

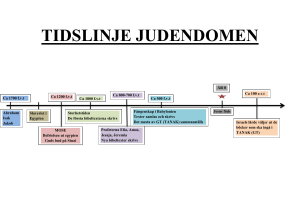
Judendom Guds utvalda folk - förbundsfolket Källor De bibliska berättelserna är de viktigaste källorna till judarnas allra tidigaste historia. Finns ej några andra källor som kan bekräfta att populära gestalter som Abraham, Mose och David verkligen har funnits. Judendomens historia Judarnas historia börjar med Abraham, ca 2000 f. v. t. Abraham får en kallelse av Gud att bege sig till Kanaans land. Gud lovade Kanaan som hemland åt Abraham och alla hans efterkommande. När Abraham kom fram till landet skulle han bli stamfader till ett stort folk. Judendomens historia Gud ingår ett förbund med Abraham. Som ett tecken på det förbund skulle Abraham och hans efterkommande av manligt kön låta sig omskära sig. Judendomens historia Judarnas härstamning gick vidare med Saras och Abrahams son Isak och senare hans son Jakob. Abraham, Isak och Jakob kallas även för de tre patriarkerna – fäderna. En av de mest betydande berättelser i Tanak är den om Mose. Moses uppgift är att föra judarna ut ur Egypten tillbaka till Kanaans land. Förbundet förnyas Denna händelse kallas för exodus (uttåget) och placeras ca 1200 f. v. t. Judendomens historia Konungatiden, ca 1000-700 f. v. t. Templet byggs. Babyloniska fångenskapen, 586 f. v. t. Templet rivs. 50 år senare bygger man upp det igen. Det är vid den babyloniska fångenskapen som judarnas längtan till landet Israel på allvar föds. Längtan till landet är en del av den judiska tron. Judendomens historia 70 v. t. förstörs det andra templet Livet i diaspora (förskringen) ca 70 v. t. till 1948, då staten Israel bildas. Sedan 70 v. t. fram till 1948 har judarna alltid levt i minoritet, spridda runt jordens alla länder. Den judiska läran Det finns en enda Gud. Den enda Guden är det mest heliga i den judiska religionen. Gud finns överallt, men går ej att se. Guds namn är så heligt att det inte får uttalas. Guds löfte om att Israel är judarnas förlovade land. I Tanak lovar Gud flera gånger att hans utvalda folk ska få leva i Kanaans land. Den judiska läran Israel som det folk som bland jordens alla folk har blivit utvalt av Gud. Gud upprättade ett förbund med judarna. Att vara jude innebär därför lika mycket att tillhöra ett folk som att tillhöra en religion. Många judar ser det som att de föds med en livsuppgift. De ska visa och förklara vad Gud vill för andra folk. Håller de fast vid förbundet kommer hela världen till slut bli rättvis och god. Alla människor är skapade till Guds avbild och lika mycket värda. Det finns många sätt att leva ett liv som Gud uppskattar, alla behöver inte vara judar. Den judiska läran Jerusalem som centralort för Israels gudsdyrkan. Den judiska läran Israel som det folk som bland jordens alla folk har blivit utvalt av Gud. Gud upprättade ett förbund med judarna. Att vara jude innebär därför lika mycket att tillhöra ett folk som att tillhöra en religion. Många judar ser det som att de föds med en livsuppgift. De ska visa och förklara vad Gud vill för andra folk. Håller de fast vid förbundet kommer hela världen till slut bli rättvis och god. Alla människor är skapade till Guds avbild och lika mycket värda. Det finns många sätt att leva ett liv som Gud uppskattar, alla behöver inte vara judar. Gudssyn och människosyn Gudssyn Gud är en Är verksam i historien Guds namn är JHVH (Jahve) Adonai (Herren) Elohim (Gud) Messias Väntar på Upprätta fredsrike Människosyn Guds ställföreträdare Medarbetare till Gud Människan har en fri vilja och ett moraliskt ansvar Livet efter döden Finns ej någon enhetlig bestämd uppfattning om livet efter döden. Judendomen intresserar sig mest för livet i den här världen. Men en vanlig uppfattning är att vid kroppens död släpps själen fri för att på något sätt återvända till Gud. Det fridsrike som beskrivs i Tanak uppfattas inte som ett paradis efter döden utan i denna värld. Heliga handlingar Judendom är handlingens religion. Det är inte vad man tänker, känner eller tror som är det viktiga utan vad man faktiskt gör. Exempel på heliga handlingar: Goda gärningar Dagliga böner Koshermat Omskärelse Barmitzva/bat mitzva Sabbaten Helig skrift Tanak ställs samman ca 200 f. v. t. De skriftlärda samlades och granskade alla de heliga skrifterna, dessa sammanställdes sedan till den hebreiska bibeln. Tanak består av tre delar: Tanak har 24 böcker. Tanak blev den samlande plattformen för det judiska folkets historiska och religiösa erfarenheter. Tora (de fem moseböckerna) Neviim (profeter) Ketuvim (skrifter) Tora = 5 böcker Neviim = 8 böcker Ketuvim = 11 böcker Tanaks språk är hebreiska med undantag för delar av Daniel och Esra, som är på arameiska.