!")
Ett sannolikhetsproblem – fördelning av fel
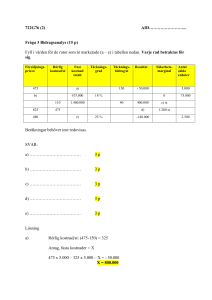
Antag att vi har en process med sex positioner och att man avsynat 1800 detaljer, 300 per position,
och funnit exakt 3 felaktiga, och sålunda 1797 ej felaktiga, detaljer. Alla de tre felaktiga detaljerna
kommer från samma position. (Beskrivningen kommer från ett verkligt problem.)
Vad är sannolikheten för denna händelse, dvs att alla 3 felaktiga kommer från en och samma position då man kontrollerar 1800 produkter (300 per position)? Kan det vara ett utslag av slumpen
eller är det ett tydligt tecken på att det är något fel produktionspositionen?
Observera att det finns ingen osäkerhet i ovanstående fakta och att problemet inte handlar om att
skatta processens felkvot.
Beräkningen av sannolikheten baseras på den klassiska definitionen 'antal gynnsamma' dividerat
med 'antal möjliga' och beräknas med 'n över x' (binomialkoefficient, se nätet för mer info).
1. 'Antal gynnsamma fall' och 'antal möjliga fall'
2. Ett approximativt synsätt
3. Ett mindre stickprov
4. Avslutande kommentarer
1. 'Antal gynnsamma fall' och 'antal möjliga fall'
'Antal möjliga fall'. Antag att vi skall lägga ut en rad bestående av 3 felaktiga (x) och 1797 ej
felaktiga produkter. På hur många sätt kan detta göras? Det utfall (den rad) man faktiskt fick vid
den verkliga inspektionen var ju bara ett av många utfall. Hur många möjliga fall finns det? Detta
kan beräknas på följande sätt (och blir ett väldigt stort tal). n = 1800, x = 3:
⎛ n ⎞
n!
1800!
1800⋅ 1799⋅ 1798⋅ 1797! 1800⋅ 1799⋅ 1798
=
=
=
⎜ ⎟ =
1797!⋅3!
3⋅ 2
⎝ x ⎠ (n − x)!⋅ x! (1800 − 3)!⋅3!
'Antal gynnsamma fall'. Av alla möjliga utfall så finns det ett visst antal som är 'gynnsamma' dvs
€
alla de möjliga utfall av 3 felaktiga i samma position. Detta beräknas på samma sätt:
300!
300⋅ 299⋅ 298⋅ 297! 300⋅ 299⋅ 298
=
=
(300 − 3)!⋅3!
297!⋅3!
3⋅ 2
Kvoten av dessa blir:
€
300⋅ 299⋅ 298
⎛ 1 ⎞ 3
300⋅ 299⋅ 298
3⋅ 2
=
= 0.00459 ≈ ⎜ ⎟
1800⋅ 1799⋅ 1798 1800⋅ 1799⋅ 1798
⎝ 6 ⎠
3⋅ 2
Kvoten ger dock sannolikheten att få de tre felaktiga produkterna i en viss på förhand utpekad
position men problemet hade 6 positioner. Kvoten måste alltså multipliceras med 6:
€
6⋅ 0.00459 = 0.0275
⎛ 1 ⎞ 3
6⋅ ⎜ ⎟ ≈ 0.0278
⎝ 6 ⎠
€ Hur skall detta värde, 0.0275, tolkas? Det finns en liten chans, cirka 3%, att alla 3 felakSlutsats.
€ Antagligen drar man slutsatsen att det
tiga, av slumpmässiga skäl, kommer från samma position.
inte är 'slumpmässiga skäl' utan att det finns något fel eller dylikt på den position som produceras
felaktiga produkter.
© Ing-Stat – www.ing-stat.se
Rev A . 2015-07-20 . 1(2)
2. Ett approximativt synsätt
I beskrivningen ovan hade vi en 'rad' med 1800 positioner uppdelade i sex lika sektioner. Men
antag att vi tycker att detta är ju praktiskt taget ett kontinuum (t.ex. en tråd), bestående av 6 lika
långa delar. Vi skulle ju då kunna resonera enligt nedanstående:
•
•
•
På ett 'slumpmässigt sätt' kastar vi ut en felaktig produkt på tråden och den hamnar med
sannolikheten 1 i en sektion.
Vi kastar på samma sätt ut den andra felaktiga produkten och den hamnar med sannolikheten 1/6
intill den första.
Vi kastar på samma sätt ut den tredje felaktiga produkten och den hamnar med sannolikheten 1/6
intill de två första.
Sannolikheten för detta, att alla tre hamnar i samma sektion, är 1/36 dvs 0.0278 och det är detta
värde som anges i tabellen ovan. Det är alltså en väldigt liten skillnad mellan det exakta och det
approximativa beräkningssättet.
(Obs att denna approximation fungerar bara då n är stort. Antag t.ex. att n = 12 och x = 3. I detta fall blir det 2
avsynade produkter per position och då går det ju inte att 'kasta ut' 3 felaktiga i samma position.)
3. Ett mindre stickprov
Antag att vi i stället har ett mycket mindre stickprov, säg, n = 30 men för övrigt samma förhållanden,
dvs x = 3 och 6 positioner och sålunda 5 produkter per position:
5⋅ 4⋅ 3
5⋅ 4⋅ 3
3⋅ 2
=
= 0.00246
30⋅ 29⋅ 28 30⋅ 29⋅ 28
3⋅ 2
Det är tydligt att vid låga n kan man inte göra samma approximation som ovan.
Om man skriver det matematiska
uttrycket utan siffror ser man lättare vad som händer (k är antal per
€
position):
k⋅ (k −1)⋅ (k − 2) k (k −1) (k − 2)
= ⋅
⋅
n⋅ (n −1)⋅ (n −1) n (n −1) (n − 2)
⎛ k ⎞ 3
⎝ n ⎠
När n ökar, ökar även k och man ser att kvoten går mer och mer åt ⎜ ⎟ , som alltså så småningom
€
blir en bra approximation till det värde man får vid en 'exakt beräkning'.
4. Avslutande kommentarer
€
Att göra en sannolikhetsberäkning består av åtminstone två steg:
•
•
En tydlig formulering av problemet och av den 'händelse' som vi skall beräkna sannolikheten för.
Beräkningen av ett tal p i intervallet 0 ≤ p ≤ 1.
I ovanstående exempel användes den klassiska definitionen av sannolikhet och några relativt enkla
matematiska operationer. I andra fall kan man behöva involvera mer eller mindre avancerade
sannolikhetsfördelningar eller rent av approximationer eller till och med simuleringar för att få
åtminstone ett approximativt värde på den sökta sannolikheten. ■
© Ing-Stat – www.ing-stat.se
Rev A . 2015-07-20 . 2(2)
!")